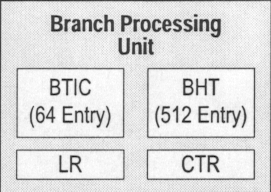
The G4 uses a Branch Processing Unit (BPU) that receives branch instructions from the sequential fetcher and resolves the conditional branches as early as possible using both static and dynamic branch prediction, achieving the effect of a zero-cycle branch in many cases.
The G4 uses dynamic prediction via a 512-entry branch history table (BHT, or what we would call a branch prediction table). This uses a 2 bit scheme that allows 4 levels of prediction:
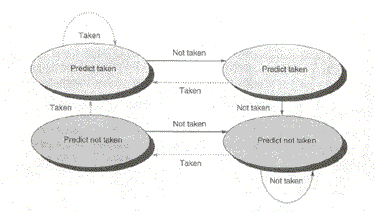
Let's assume the status of a particular branch is initially strongly not-taken (00). If in the next occurrence of the branch it is taken, its BHT is updated to 01, or not-taken. Once taken again, this branch crosses the line to strongly taken (11) where one not-taken would cause it to drop only to taken (10), but another not-taken causes it to fall all the way to 00. However, at 10 a taken will bring it back up to strongly taken. As one can see, it takes two consecutive takens to switch the actual prediction from not-taken to taken and two consecutive not-takens for the actual prediction to change from taken to not-taken.
The G4 works just like the DLX discussed in class, in that once a prediction is made, it continues to execute instructions based on the prediction until it is known to be a bad prediction. If that occurs, the pipe is flushed and it then executes the correct instructions. One time-saving feature is that the G4 actually fetches two instructions based on a prediction and if the one it executes based on the prediction is wrong, it has a "backup" to use immediately after flushing the pipe. This works because most branches (such as while loops, for loops, if statements, etc.) have just two possible next instructions, the one that depends on the conditional/loop and the one directly after the conditional/loop, as in the following example:
|
if (x == 5) x = x + 1; x = x - 5; |
// branch // fetches this instructions because it depends on branch // also fetches this one, as it's the one directly after brach |
How does that work? With the G4's BTIC (Branch Target Instruction Cache, or Branch Target Buffer in Meeshese). The BTIC is a 64-entry, four-way set associative cache (for explanation of what that means, see cache) that contains the most recently used branch target instructions, typically in pairs. Knowing what the next instruction should be allows the instructions to arrive in the instruction queue one clock cycle sooner than they would otherwise, directly out of the instruction cache. Thus, the BTIC reduces the number of missed opportunities to dispatch instructions and gives the processor a one-cycle head start on processing the target stream.
An additional efficiency feature found in the BPU is its use of extra registers and an adder for calculating addresses. The three registers are the link register (LR), the count register (CTR) and the condition register (CR). The calculated return pointers are stored in the LR along with the branch target address for the Branch Conditional to Link Register (bclrx) instruction. The CTR has the branch target address for the Branch Conditional to Count Register(bcctrx) instruction. Both the LR and CTR are special purpose registers, their contents can be copied to or from any GPR (registers for integer values). These dedicated registers result in the execution of branch instructions being independent from execution of integer and floating-point instructions.