11 Pipeline Hazards
Dr A. P. Shanthi
The objectives of this module are to discuss the various hazards associated with pipelining.
We discussed the basics of pipelining and the MIPS pipeline implementation in the previous module. We made the following observations about pipelining:
- Pipelining doesn’t help latency of single task, it helps throughput of entire workload
- Pipeline rate limited by slowest pipeline stage o Multiple tasks operating simultaneously
- Potential speedup = Number of pipe stages
- Unbalanced lengths of pipe stages reduces speedup
- Time to “fill” pipeline and time to “drain” it reduces speedup o Unbalanced lengths of pipe stages reduces speedup
- Execute billions of instructions, so throughput is what matters o Data path design – Ideally we expect a CPI value of 1
- What is desirable in instruction sets for pipelining?
- Variable length instructions vs. all instructions same length?
- Memory operands part of any operation vs. memory operands only in loads or stores?
- Register operand many places in instruction format vs. registers located in same place?
Ideally we expect a CPI value of 1 and a speedup equal to the number of stages in the pipeline. But, there are a number of factors that limit this. The problems that occur in the pipeline are called hazards. Hazards that arise in the pipeline prevent the next instruction from executing during its designated clock cycle. There are three types of hazards:
- Structural hazards: Hardware cannot support certain combinations of instructions (two instructions in the pipeline require the same resource).
- Data hazards: Instruction depends on result of prior instruction still in the pipeline
- Control hazards: Caused by delay between the fetching of instructions and decisions about changes in control flow (branches and jumps).
Structural hazards arise because there is not enough duplication of resources.
Resolving structural hazards:
- Solution 1: Wait
o Must detect the hazard
o Must have mechanism to stall
o Low cost and simple
o Increases CPI
o Used for rare cases
- Solution 2: Throw more hardware at the problem
o Pipeline hardware resource
§ useful for multi-cycle resources
§ good performance
§ sometimes complex e.g., RAM
o Replicate resource
§ good performance
§ increases cost (+ maybe interconnect delay)
§ useful for cheap or divisible resource
Figure 11.1 shows one possibility of a structural hazard in the MIPS pipeline. Instruction 3 is accessing memory for an instruction fetch and instruction 1 is accessing memory for a data access (load/store). These two are conflicting requirements and gives rise to a hazard. We should either stall one of the operations as shown in Figure 11.2, or have two separate memories for code and data. Structural hazards will have to handled at the design time itself.
Next, we shall discuss about data dependences and the associated hazards. There are two types of data dependence – true data dependences and name dependences.
• An instruction j is data dependent on instruction i if either of the following holds:
– Instruction i produces a result that may be used by instruction j, or
– Instruction j is data dependent on instruction k, and instruction k is data dependent on instruction i
• A name dependence occurs when two instructions use the same register or memory location, called a name, but there is no flow of data between the instructions associated with that name
– Two types of name dependences between an instruction i that precedes instruction j in program order:
– An antidependence between instruction i and instruction j occurs when instruction j writes a register or memory location that instruction i reads. The original ordering must be preserved.
– An output dependence occurs when instruction i and instruction j write the same register or memory location. The ordering between the instructions must be preserved.
– Since this is not a true dependence, renaming can be more easily done for register operands, where it is called register renaming
– Register renaming can be done either statically by a compiler or dynamically by the hardware
Last of all, we discuss control dependences. Control dependences determine the ordering of an instruction with respect to a branch instruction so that an instruction i is executed in correct program order. There are two general constraints imposed by control dependences:
– An instruction that is control dependent on its branch cannot be moved before the branch so that its execution is no longer controlled by the branch.
– An instruction that is not control dependent on its branch cannot be moved after the branch so that its execution is controlled by the branch.
Having introduced the various types of data dependences and control dependence, let us discuss how these dependences cause problems in the pipeline. Dependences are properties of programs and whether the dependences turn out to be hazards and cause stalls in the pipeline are properties of the pipeline organization.
Data hazards may be classified as one of three types, depending on the order of read and write accesses in the instructions:
- RAW (Read After Write)
- Corresponds to a true data dependence
- Program order must be preserved
- This hazard results from an actual need for communication
- Considering two instructions i and j, instruction j reads the data before i writes it
i: ADD R1, R2, R3
j: SUB R4, R1, R3
Add modifies R1 and then Sub should read it. If this order is changed, there is a RAW hazard
- WAW (Write After Write)
- Corresponds to an output dependence
- Occurs when there are multiple writes or a short integer pipeline and a longer floating-point pipeline or when an instruction proceeds when a previous instruction is stalled WAW (write after write)
- This is caused by a name dependence. There is no actual data transfer. It is the same name that causes the problem
- Considering two instructions i and j, instruction j should write after instruction i has written the data
i: SUB R1, R4, R3
j: ADD R1, R2, R3
Instruction i has to modify register r1 first, and then j has to modify it. Otherwise, there is a WAW hazard. There is a problem because of R1. If some other register had been used, there will not be a problem
- Solution is register renaming, that is, use some other register. The hardware can do the renaming or the compiler can do the renaming
- WAR (Write After Read)
- Arises from an anti dependence
- Cannot occur in most static issue pipelines
- Occurs either when there are early writes and late reads, or when instructions are re-ordered
- There is no actual data transfer. It is the same name that causes the problem
- Considering two instructions i and j, instruction j should write after instruction i has read the data.
i: SUB R4, R1, R3
j: ADD R1, R2, R3
Instruction i has to read register r1 first, and then j has to modify it. Otherwise, there is a WAR hazard. There is a problem because of R1. If some other register had been used, there will not be a problem
• Solution is register renaming, that is, use some other register. The hardware can do the renaming or the compiler can do the renaming
Figure 11.3 gives a situation of having true data dependences. The use of the result of the ADD instruction in the next three instructions causes a hazard, since the register is not written until after those instructions read it. The write back for the ADD instruction happens only in the fifth clock cycle, whereas the next three instructions read the register values before that, and hence will read the wrong data. This gives rise to RAW hazards.
A control hazard is when we need to find the destination of a branch, and can’t fetch any new instructions until we know that destination. Figure 11.4 illustrates a control hazard. The first instruction is a branch and it gets resolved only in the fourth clock cycle. So, the next three instructions fetched may be correct, or wrong, depending on the outcome of the branch. This is an example of a control hazard.
Now, having discussed the various dependences and the hazards that they might lead to, we shall see what are the hazards that can happen in our simple MIPS pipeline.
- Structural hazard
- Conflict for use of a resource
• In MIPS pipeline with a single memory
– Load/store requires data access
– Instruction fetch would have to stall for that cycle
• Would cause a pipeline “bubble”
• Hence, pipelined datapaths require separate instruction/data memories or separate instruction/data caches
- RAW hazards – can happen in any architecture
- WAR hazards – Can’t happen in MIPS 5 stage pipeline because all instructions take 5 stages, and reads are always in stage 2, and writes are always in stage 5
- WAW hazards – Can’t happen in MIPS 5 stage pipeline because all instructions take 5 stages, and writes are always in stage 5
- Control hazards
- Can happen
- The penalty depends on when the branch is resolved – in the second clock cycle or the third clock cycle
- More aggressive implementations resolve the branch in the second clock cycle itself, leading to one clock cycle penalty
Let us look at the speedup equation with stalls and look at an example problem.
CPIpipelined = Ideal CPI + Average Stall cycles per Inst
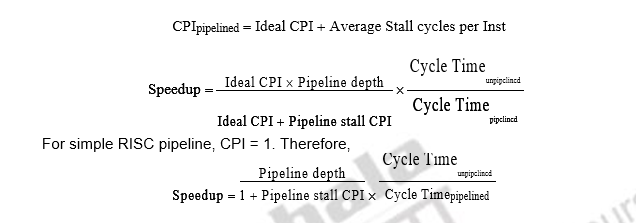
Let us assume we want to compare the performance of two machines. Which machine is faster?
- Machine A: Dual ported memory – so there are no memory stalls
- Machine B: Single ported memory, but its pipelined implementation has a 1.05 times faster clock rate
Assume:
- Ideal CPI = 1 for both
- Loads are 40% of instructions executed
SpeedupA = Pipeline Depth/(1+0) x(clockunpipe/clockpipe)
= Pipeline Depth
SpeedupB = Pipeline Depth/(1 + 0.4 x 1) x (clockunpipe/(clockunpipe / 1.05)
= (Pipeline Depth/1.4) x 1.05
= 75 x Pipeline Depth
SpeedupA / SpeedupB = Pipeline Depth / (0.75 x Pipeline Depth) = 1.33 Machine A is 1.33 times faster.
To summarize, we have discussed the various hazards that might occur in a pipeline. Structural hazards happen because there are not enough duplication of resources and they have to be handled at design time itself. Data hazards happen because of true data dependences and name dependences. Control hazards are caused by branches. The solutions for all these hazards will be discussed in the subsequent modules.
Web Links / Supporting Materials
- Computer Organization and Design – The Hardware / Software Interface, David A. Patterson and John L. Hennessy, 4th.Edition, Morgan Kaufmann, Elsevier, 2009.
- Computer Organization, Carl Hamacher, Zvonko Vranesic and Safwat Zaky, 5th.Edition, McGraw- Hill Higher Education, 2011.