CMSC216 Project 5: Performance Opt and Threading
- Due: 11:59pm Mon 09-Dec-2024
- Approximately 3.0-4.0% of total grade
- Submit to Gradescope
- Projects are individual work: no collaboration with other students is allowed. Seek help from course staff if you get stuck for too long.
CODE/TEST DISTRIBUTION: p5-code.zip
Video Overview: https://youtu.be/Uv7UPc02xlc
CHANGELOG:
- Sun Dec 8 12:21:37 PM EST 2024
- Submission for P5 is open on Gradescope after a delay to resolve technical problems with the Autograder. Students will NOT see their performance score for Problem 2 as this must use GRACE to run. Later, graders will assign scores based on the best of 3 runs on an odd GRACE node.
- Thu Dec 5 04:38:08 PM EST 2024
- Typo fix for the value returned
for
mmap()according to Post 2217. - Mon Dec 2 03:36:15 PM EST 2024
- A video overview of the project has been posted here: https://youtu.be/Uv7UPc02xlc
- Mon Dec 2 10:36:51 AM EST 2024
- Corrected typos in the codepack listing which incorrectly listed source files from a previous version of Problem 2.
Table of Contents
- 1. Introduction
- 2. Download Code and Setup
- 3. Problem 1 : EL Malloc
- 3.1. EL Malloc Data Structures
- 3.2. Block Header/Footer
- 3.3. Blocks Above/Below
- 3.4. Block Lists and Global Control
- 3.5. Pointers and "Actual" Space
- 3.6. Doubly Linked List Operations
- 3.7. Allocation via Block Splitting
- 3.8. Freeing Blocks and Merging
- 3.9. Expanding the Heap
- 3.10. Overall Code Structure of EL Malloc
- 3.11. Demo Run using EL Malloc
- 3.12. Grading Criteria for Problem 1
- 4. Problem 2: Matrix Column Normalization
- 5. Assignment Submission
1 Introduction
This project features a two required problems pertaining to the final topics discussed in the course.
- EL Malloc implements a simple, explicit list memory allocator.
This manages heap memory in doubly linked lists of Available and
Used memory blocks to provide
el_malloc() / el_free(). It could be extended with some work to be a drop-in replacement formalloc() / free(). - A baseline implementation for a function operating on a matrix is provided and students will create an optimzied version of it which calculates the same result but in a shorter time. Doing so will involve exploiting knowledge of the memory hierarchy to favor cache and enabling multi-threading to further boost perforamnce.
2 Download Code and Setup
Download the code pack linked at the top of the page. Unzip this which will create a project folder. Create new files in this folder. Ultimately you will re-zip this folder to submit it.
| File | State | Notes |
|---|---|---|
Makefile |
Provided | Problem 1 & 2 Build file |
testy |
Testing | Test running script |
el_malloc.h |
Provided | Problem 1 header file |
el_demo.h |
Provided | Problem 1 demo main() |
el_malloc.c |
COMPLETE | Problem 1 implemented REQUIRED functions |
test_el_malloc.c |
Testing | Problem 1 Testing program for El Malloc |
test_el_malloc.org |
Testing | Problem 1 Testing script for El Malloc |
colnorm_optm.c |
EDIT | Problem 2 create and fill in optimized function definition |
colnorm_benchmark.c |
Provided | Problem 2 main benchmark |
colnorm_print.c |
Provided | Problem 2 testing program |
colnorm_base.c |
Provided | Problem 2 baseline function to beat |
colnorm.h |
Provided | Problem 2 header file |
colnorm_util.c |
Provided | Problem 2 utility functions for matrices/vectors |
test_colnorm.org |
Testing | Tests to check for memory issues in problem 2 |
3 Problem 1 : EL Malloc
A memory allocator is small system which manages heap memory,
sometimes referred to as the "data" segment of a program. This
portion of program memory is a linear set of addresses that form a
large block which can expand at runtime by making requests to the
operating system. Solving the allocation problem forms backbone of
what malloc()/free() do by keeping track of the space used and
released by a user program. Allocators also see use in garbage
collected languages like Java where there are no explicit free()
calls but the allocator must still find available space for new
objects.
One simple way to implement an allocator is to overlay linked lists on the heap which track at a minimum the available chunks of memory and possibly also the used chunks. This comes with a cost: some of the bytes of memory in the heap are no longer available for the user program but are instead used for the allocator's book-keeping.
In this problem, an explicit list allocator is developed, thus the
name of the system el_malloc. It uses two lists to track memory in
the heap:
- The Available List of blocks of memory that can be used to answer
calls to
malloc() - The Used List of blocks that have been returned by
malloc()and should not be returned again until they arefree()'d
Most operations boil down to manipulating these two lists in some form.
- Allocating with
ptr = el_malloc(size);searches the Available List for a block with sufficient size. That block is split into two blocks. One block answers the request and is given aboutsizebytes; it is moved to the Used List. The second block comprises the remainder of the space and remains on the Available List. - Deallocating with
el_free(ptr);moves the block referenced byptrfrom the Used List to the Available List. To prevent fragmentation of memory, the newly available block is merged with adjacent available blocks if possible.
3.1 EL Malloc Data Structures
Several data structures defined in el_malloc.h should be studied so
that one is acquainted with their intent. The following sections
outline many of these and show diagrams to indicate transformation
the required functions should implement.
3.2 Block Header/Footer
Each block of memory tracked by EL Malloc is preceded and succeeded by
some bytes of memory for book keeping. These are referred to as the
block "header" and "footer" and are encoded in the el_blockhead_t
and el_blockfoot_t structs.
// type which is a "header" for a block of memory; containts info on
// size, whether the block is available or in use, and links to the
// next/prev blocks in a doubly linked list. This data structure
// appears immediately before a block of memory that is tracked by the
// allocator.
typedef struct block {
size_t size; // number of bytes of memory in this block
char state; // either EL_AVAILABLE or EL_USED
struct block *next; // pointer to next block in same list
struct block *prev; // pointer to previous block in same list
} el_blockhead_t;
// Type for the "footer" of a block; indicates size of the preceding
// block so that its header el_blockhead_t can be found with pointer
// arithmetic. This data appears immediately after an area of memory
// that may be used by a user or is free. Immediately after it is
// either another header (el_blockhead_t) or the end of the heap.
typedef struct {
size_t size;
} el_blockfoot_t;
As indicated, the blocks use doubly linked nodes in the header which will allow easy re-arrangement of the list.
A picture of a block with its header, footer, and user data area is shown below.
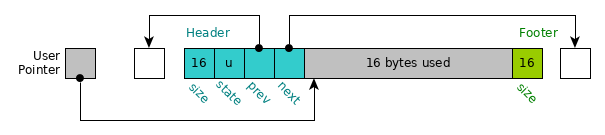
Figure 1: Block data preceded by a header (el_blockhead_t) and followed by a footer (el_blockfoot_t)._
3.3 Blocks Above/Below
One might wonder why the footer appears. In tracking blocks, there will arise the need to work with a block that immediately precedes given block in memory in memory (not the previous in the linked list). The footer enables this by tracking the size of the user block of memory immediately beneath it.
This is illustrated in the diagram below.
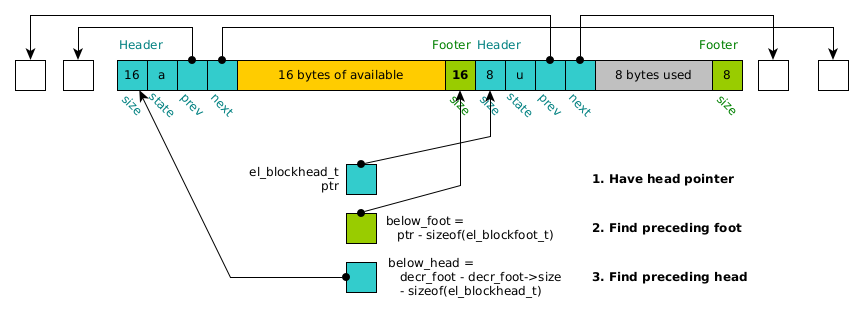
Figure 2: Finding preceding block header using footer (el_block_below(header))
This operation is implemented in the function el_block_below(block) and
the similar operation el_block_above(block) finds the next header
immediately following one in memory.
The following functions use pointer arithmetic to determine block locations from a provided pointer.
el_blockfoot_t *el_get_footer(el_blockhead_t *block); el_blockhead_t *el_get_header(el_blockfoot_t *foot); el_blockhead_t *el_block_above(el_blockhead_t *block); el_blockhead_t *el_block_below(el_blockhead_t *block);
These functions benefit from macros defined in el_malloc.h that are
useful for doing pointer operations involving bytes.
// macro to add a byte offset to a pointer, arguments are a pointer // and a # of bytes (usually size_t) #define PTR_PLUS_BYTES(ptr,off) ((void *) (((size_t) (ptr)) + ((size_t) (off)))) // macro to add a byte offset to a pointer, arguments are a pointer // and a # of bytes (usually size_t) #define PTR_MINUS_BYTES(ptr,off) ((void *) (((size_t) (ptr)) - ((size_t) (off)))) // macro to add a byte offset to a pointer, arguments are a pointer // and a # of bytes (usually size_t) #define PTR_MINUS_PTR(ptr,ptq) (((size_t) (ptr)) - ((size_t) (ptq)))
3.4 Block Lists and Global Control
The main purpose of the memory allocator is to track the available and used blocks in explicit linked lists. This allows used and available memory to be distributed throughout the heap. Below are the data structures that track these lists and the global control data structure which houses information for the entire heap.
// Type for a list of blocks; doubly linked with a fixed
// "dummy" node at the beginning and end which do not contain any
// data. List tracks its length and number of bytes in use.
typedef struct {
el_blockhead_t beg_actual; // fixed node at beginning of list; state is EL_BEGIN_BLOCK
el_blockhead_t end_actual; // fixed node at end of list; state is EL_END_BLOCK
el_blockhead_t *beg; // pointer to beg_actual
el_blockhead_t *end; // pointer to end_actual
size_t length; // length of the used block list (not counting beg/end)
size_t bytes; // total bytes in list used including overhead;
} el_blocklist_t;
// NOTE: total available bytes for use/in-use in the list is (bytes - length*EL_BLOCK_OVERHEAD)
// Type for the global control of the allocator. Tracks heap size,
// start and end addresses, total size, and lists of available and
// used blocks.
typedef struct {
void *heap_start; // pointer to where the heap starts
void *heap_end; // pointer to where the heap ends; this memory address is out of bounds
size_t heap_bytes; // number of bytes currently in the heap
el_blocklist_t avail_actual; // space for the available list data
el_blocklist_t used_actual; // space for the used list data
el_blocklist_t *avail; // pointer to avail_actual
el_blocklist_t *used; // pointer to used_actual
} el_ctl_t;
The following diagram shows some of the structure induced by use of a
doubly linked lists overlaid onto the heap. The global control
structure el_ctl has two lists for available and used space.
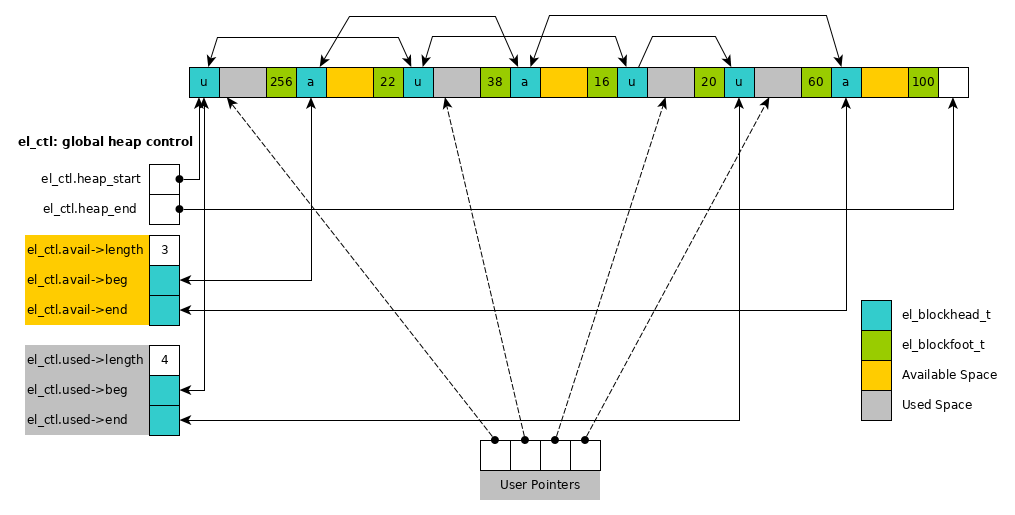
Figure 3: Structure of heap with several used/available blocks. Pointers from el_ctl lists allow access to these blocks.
The following functions initialize the global control structures, print stats on the heap, and clean up at the end of execution.
int el_init(int max_bytes); void el_print_stats(); void el_cleanup();
3.5 Pointers and "Actual" Space
In several structures, there appear pointers named xxx and structs
named xxx_actual. For example, in el_blocklist_t:
typedef struct {
...
el_blockhead_t beg_actual; // fixed node at beginning of list; state is EL_BEGIN_BLOCK
el_blockhead_t *beg; // pointer to beg_actual
...
} el_blocklist_t;
The intent here is that there will always be a node at the beginning
of the doubly linked list to make the programming easier. It makes
sense to have an actual struct beg_actual present. However, when
working with the list, the address of the beginning node is often
referenced making beg useful. In any case, beg will be initialized
to &beg_actual as appears in el_init_blocklist().
void el_init_blocklist(el_blocklist_t *list){
list->beg = &(list->beg_actual);
list->beg->state = EL_BEGIN_BLOCK;
list->beg->size = EL_UNINITIALIZED;
...
}
Similarly, since there will always be an Available List, el_ctl_t
has both an avail pointer to the list and avail_actual which is
the struct for the list.
3.6 Doubly Linked List Operations
A large number of operations in EL Malloc boil down to doubly linked list operations. This includes
- Unlinking nodes from the middle of list during
el_free() - Adding nodes to the beginning of a headed list (allocation and free)
- Traversing the list to print and search for available blocks
Recall that unlinking a node from a doubly linked list involves modifying the previous and next node as in the following.
node->prev->next = node->next; node->next->prev = node->prev;
while adding a new node to the front is typically accomplished via
node->prev = list->beg; node->next = list->beg->next; node->prev->next = node; node->next->prev = node;
You may wish to review doubly linked list operations and do some reading on lists with "dummy" nodes at the beginning and ending if these concepts are rusty.
The following functions pertain to block list operations.
void el_init_blocklist(el_blocklist_t *list); void el_print_blocklist(el_blocklist_t *list); void el_add_block_front(el_blocklist_t *list, el_blockhead_t *block); void el_remove_block(el_blocklist_t *list, el_blockhead_t *block);
3.7 Allocation via Block Splitting
The basic operation of granting memory on a call to el_malloc(size)
involves finding an Available Block with enough bytes for the
requested amount of memory. In the event that the block is
significantly larger than the request and has enough space for a new
header and footer, it can be split into two blocks with one granting
the user request and another representing the remaining space.
This process is demonstrated in the below diagram in which a request
for some bytes has been made. It first shows the rough behavior in two
cases of the el_split_block() function. During el_malloc(), on
searches the Available List for a block with enough space. Once
found, the block is split into the portion that will be used and the
remaining portion if possible. A pointer to the user area immediately
after the el_blockhead_t is returned from el_malloc().
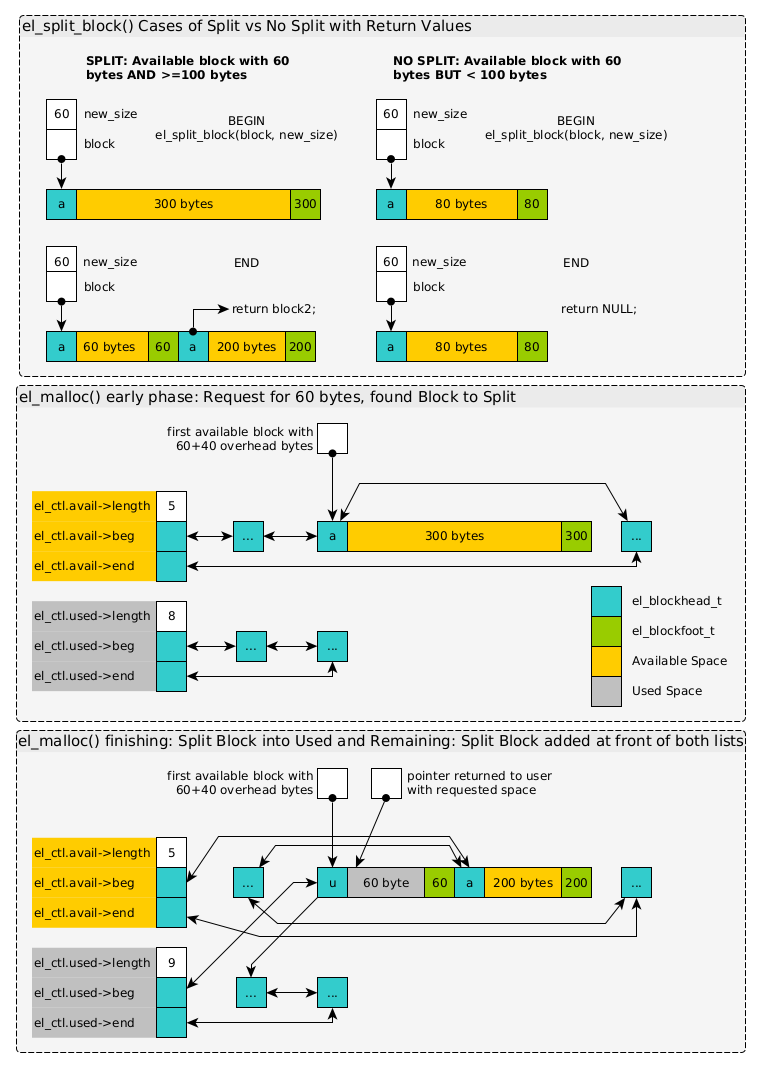
Figure 4: Splitting a block in an allocation request. Top panels shows the behavior of the el_split_block() function. Bottom panels show the beginning and ending state of el_malloc() and one possibility of splitting a block affects the used and available lists.
The following functions pertain to the location and splitting of blocks in the available list to fulfill allocation requests.
el_blockhead_t *el_find_first_avail(size_t size); el_blockhead_t *el_split_block(el_blockhead_t *block, size_t new_size); void *el_malloc(size_t nbytes);
3.8 Freeing Blocks and Merging
Freeing memory passes in a pointer to the user area that was
granted. Immediately preceding this should be a el_blockhead_t and
it can be found with pointer arithmetic.
In order to prevent memory from becoming continually divided into
smaller blocks, on freeing the system checks to see if adjacent blocks
can be merged. Keep in mind that the blocks that can be merged are
adjacent in memory, not next/previous in some linked list. Adjacent
blocks can be located using el_block_above() and el_block_below().
To merge, the adjacent blocks must both be Available (not Used). A free can then have several cases.
- The freed block cannot be merged with any others
- The freed block can be merged with only the block above it
- The freed block can be merged with only the block below it
- The freed block can be merged with both adjacent blocks
The diagrams below show two of these cases.
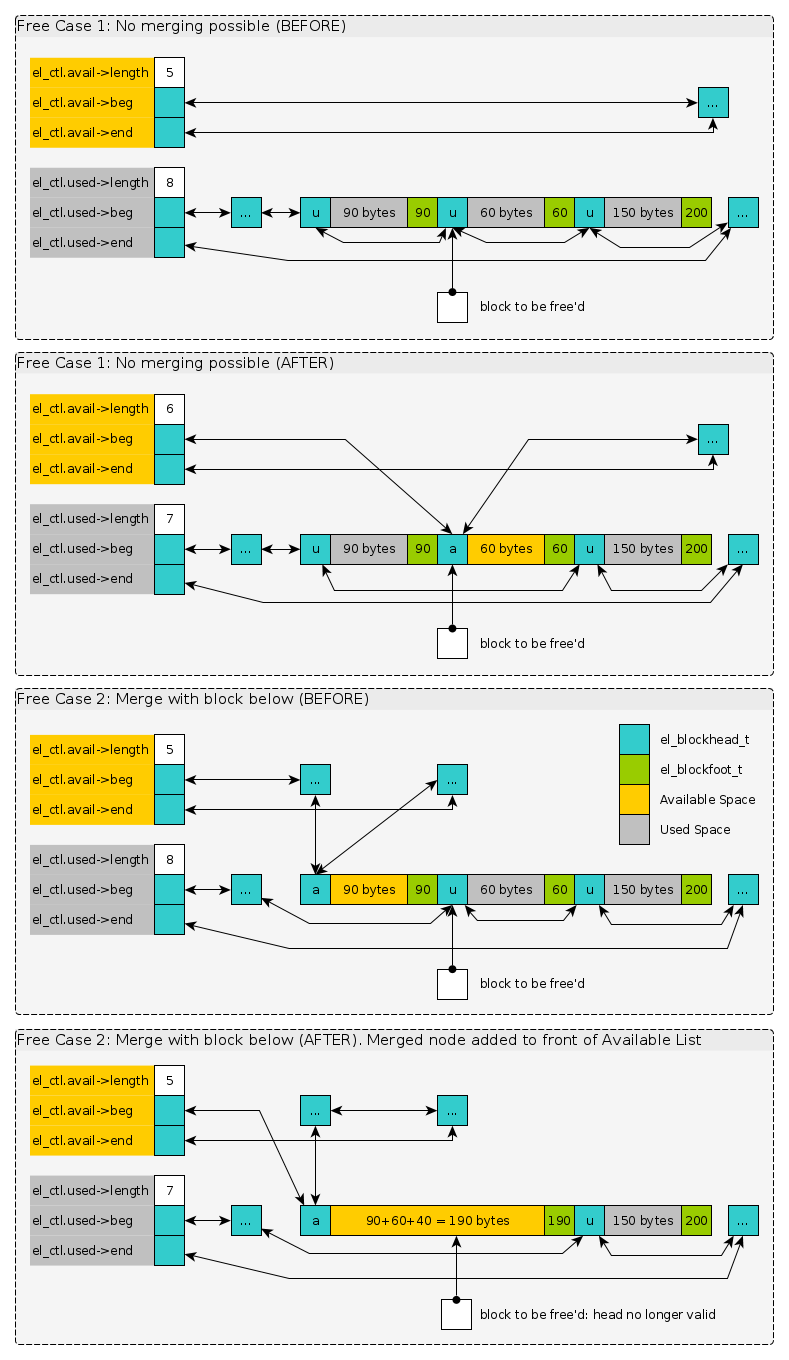
Figure 5: Two cases of freeing blocks. The 2nd involves merging adjacent nodes with available space.
With careful use of the below functions and handling of NULL
arguments, all 4 cases can be handled with very little code. Keep in
mind that el_block_above()/below() should return NULL if there is
no block above or below due to that are being out of the boundaries of
the heap.
el_blockhead_t *el_block_above(el_blockhead_t *block); el_blockhead_t *el_block_below(el_blockhead_t *block); void el_merge_block_with_above(el_blockhead_t *lower); void el_free(void *ptr);
3.9 Expanding the Heap
El Malloc initializes the heap with just a single page of memory
(EL_PAGE_BYTES = 4096 bytes) during el_init(). While good for
testing, a real application would need more space than this. The
beginnings of heap expansion are provided via the following
function.
int el_append_pages_to_heap(int npages); // REQUIRED // Attempts to append pages of memory to the heap with mmap(). npages // is how many pages are to be appended with total bytes to be // appended as npages * EL_PAGE_BYTES. Calls mmap() with similar // arguments to those used in el_init() however requests the address // of the pages to be at heap_end so that the heap grows // contiguously. If this fails, prints the message // // ERROR: Unable to mmap() additional 3 pages // // and returns 1. Note that mmap() returns the constant MAP_FAILED on // errors and the returned address will not match the requested // virtual address on failures. // // Otherwise, adjusts heap size and end for the expanded heap. Creates // a new block for the freshly allocated pages that is added to the // available list. Also attempts to merge this block with the block // below it. Returns 0 on success.
The central idea of the function is to allocate more space for the
heap through mmap() calls. Since it is desirable to treat the heap
a contiguous block of memory, the calls to mmap() should attempt to
map new space for the heap to the el_ctl->heap_end address thereby
"appending" the pages the heap.
Here are a few implementation notes.
- In some cases,
NULLis passed as the first argument tommap()as a user program does not care what virtual address the OS uses for pages of memory. However, El Malloc will have specific addresses that it uses for the heap start and expansion. - Analyze the provided
el_init()function which initially usesmmap()to create the heap. Many aspects of the setup function can be transferred here. - One difference is that while
el_init()allocates the heap atEL_HEAP_START_ADDRESS,el_append_pages_to_heap()should map pages starting at the heap end. This will create a continuous virtual memory space for the heap as it expands. - If
mmap()fails, it does NOT returnNULLand rather returns a special constantMAP_FAILEDwhich will be different from the requested address. Check ifmmap()succeeds or fails based on this constant and print the error message indicated if so.
3.10 Overall Code Structure of EL Malloc
Below is the code structure of the EL Malloc library. Some of the
functions have been implemented already while those marked REQUIRED
must be completed for full credit on the problem.
// el_malloc.c: implementation of explicit list malloc functions.
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include "el_malloc.h"
////////////////////////////////////////////////////////////////////////////////
// Global control functions
el_ctl_t *el_ctl = NULL;
// Global control variable for the allocator. Must be initialized in
// el_init().
int el_init();
// Create an initial block of memory for the heap using
// mmap(). Initialize the el_ctl data structure to point at this
// block. The initializ size/position of the heap for the memory map
// are given in the symbols EL_HEAP_INITIAL_SIZE and
// EL_HEAP_START_ADDRESS. Initialize the lists in el_ctl to contain a
// single large block of available memory and no used blocks of
// memory.
void el_cleanup();
// Clean up the heap area associated with the system which unmaps all
// pages associated with the heap.
////////////////////////////////////////////////////////////////////////////////
// Pointer arithmetic functions to access adjacent headers/footers
el_blockfoot_t *el_get_footer(el_blockhead_t *head);
// Compute the address of the foot for the given head which is at a
// higher address than the head.
el_blockhead_t *el_get_header(el_blockfoot_t *foot);
// REQUIRED
// Compute the address of the head for the given foot which is at a
// lower address than the foot.
el_blockhead_t *el_block_above(el_blockhead_t *block);
// Return a pointer to the block that is one block higher in memory
// from the given block. This should be the size of the block plus
// the EL_BLOCK_OVERHEAD which is the space occupied by the header and
// footer. Returns NULL if the block above would be off the heap.
// DOES NOT follow next pointer, looks in adjacent memory.
el_blockhead_t *el_block_below(el_blockhead_t *block);
// REQUIRED
// Return a pointer to the block that is one block lower in memory
// from the given block. Uses the size of the preceding block found
// in its foot. DOES NOT follow block->next pointer, looks in adjacent
// memory. Returns NULL if the block below would be outside the heap.
//
// WARNING: This function must perform slightly different arithmetic
// than el_block_above(). Take care when implementing it.
////////////////////////////////////////////////////////////////////////////////
// Block list operations
void el_print_blocklist(el_blocklist_t *list);
// Print an entire blocklist. The format appears as follows.
//
// {length: 2 bytes: 3400}
// [ 0] head @ 0x600000000000 {state: a size: 128}
// [ 1] head @ 0x600000000360 {state: a size: 3192}
//
// Note that the '@' column uses the actual address of items which
// relies on a consistent mmap() starting point for the heap.
void el_print_block(el_blockhead_t *block);
// Print a single block during a sequential walk through the heap
void el_print_heap_blocks();
// Print all blocks in the heap in the order that they appear from
// lowest addrses to highest address
void el_print_stats();
// Print out stats on the heap for use in debugging. Shows the
// available and used list along with a linear walk through the heap
// blocks.
void el_init_blocklist(el_blocklist_t *list);
// Initialize the specified list to be empty. Sets the beg/end
// pointers to the actual space and initializes those data to be the
// ends of the list. Initializes length and size to 0.
void el_add_block_front(el_blocklist_t *list, el_blockhead_t *block);
// REQUIRED
// Add to the front of list; links for block are adjusted as are links
// within list. Length is incremented and the bytes for the list are
// updated to include the new block's size and its overhead.
void el_remove_block(el_blocklist_t *list, el_blockhead_t *block);
// REQUIRED
// Unlink block from the list it is in which should be the list
// parameter. Updates the length and bytes for that list including
// the EL_BLOCK_OVERHEAD bytes associated with header/footer.
////////////////////////////////////////////////////////////////////////////////
// Allocation-related functions
el_blockhead_t *el_find_first_avail(size_t size);
// REQUIRED
// Find the first block in the available list with block size of at
// least `size`. Returns a pointer to the found block or NULL if no
// block of sufficient size is available.
el_blockhead_t *el_split_block(el_blockhead_t *block, size_t new_size);
// REQUIRED
// Set the pointed to block to the given size and add a footer to
// it. Creates another block above it by creating a new header and
// assigning it the remaining space. Ensures that the new block has a
// footer with the correct size. Returns a pointer to the newly
// created block while the parameter block has its size altered to
// parameter size. Does not do any linking of blocks. If the
// parameter block does not have sufficient size for a split (at least
// new_size + EL_BLOCK_OVERHEAD for the new header/footer) makes no
// changes tot the block and returns NULL indicating no new block was
// created.
void *el_malloc(size_t nbytes);
// REQUIRED
// Return pointer to a block of memory with at least the given size
// for use by the user. The pointer returned is to the usable space,
// not the block header. Makes use of find_first_avail() to find a
// suitable block and el_split_block() to split it. Returns NULL if
// no space is available.
////////////////////////////////////////////////////////////////////////////////
// De-allocation/free() related functions
void el_merge_block_with_above(el_blockhead_t *lower);
// REQUIRED
// Attempt to merge the block lower with the next block in
// memory. Does nothing if lower is null or not EL_AVAILABLE and does
// nothing if the next higher block is null (because lower is the last
// block) or not EL_AVAILABLE. Otherwise, locates the next block with
// el_block_above() and merges these two into a single block. Adjusts
// the fields of lower to incorporate the size of higher block and the
// reclaimed overhead. Adjusts footer of higher to indicate the two
// blocks are merged. Removes both lower and higher from the
// available list and re-adds lower to the front of the available
// list.
//
// CONSTRAINT: This function merges at most 2 blocks into 1 block. It
// does not iterate and has no need to recurse. Its primary use is
// during el_free() to potentially merge adjacent free blocks together
// to form one large free block. The heap is maintained by immediately
// merging any free blocks during el_free() so that there are never
// adjacent free blocks.
void el_free(void *ptr);
// REQUIRED
// Free the block pointed to by the give ptr. The area immediately
// preceding the pointer should contain an el_blockhead_t with information
// on the block size. Attempts to merge the free'd block with adjacent
// blocks using el_merge_block_with_above().
////////////////////////////////////////////////////////////////////////////////
// HEAP EXPANSION FUNCTIONS
int el_append_pages_to_heap(int npages);
// REQUIRED
// Attempts to append pages of memory to the heap with mmap(). npages
// is how many pages are to be appended with total bytes to be
// appended as npages * EL_PAGE_BYTES. Calls mmap() with similar
// arguments to those used in el_init() however requests the address
// of the pages to be at heap_end so that the heap grows
// contiguously. If this fails, prints the message
//
// ERROR: Unable to mmap() additional 3 pages
//
// and returns 1. Otherwise, adjusts heap size and end for the
// expanded heap. Creates a new block for the freshly allocated pages
// that is added to the available list. Also attempts to merge this
// block with the block below it. Returns 0 on success.
//
// NOTE ON mmap() USAGE: mmap() returns one of three things if a
// specific address is requested (its first argument):
//
// 1. The address requested indicating the memory mapping succeeded
//
// 2. A different address than the one requested if the requeste
// address is in use
//
// 3. The constant MAP_FAILED if the address mapping failed.
//
// #2 and #3 above should trigger this function to immediate print an
// #error message and return 1 as the heap cannot be made continuous
// #in those cases.
3.11 Demo Run using EL Malloc
Below is a run showing the behavior of a series of el_malloc() /
el_free() calls. They are performed in the provided el_demo.c
program.
Source for el_demo.c
// el_demo.c: Shows use cases for el_malloc() and el_free(). This file
// can be used for testing but is not itself a test.
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include "el_malloc.h"
void print_ptr(char *str, void *ptr){
if(ptr == NULL){
printf("%s: (nil)\n", str);
}
else{
printf("%s: %p\n", str, ptr);
}
}
int main(){
printf("EL_BLOCK_OVERHEAD: %lu\n",EL_BLOCK_OVERHEAD);
el_init();
printf("INITIAL\n"); el_print_stats(); printf("\n");
void *p1 = el_malloc(128);
void *p2 = el_malloc(48);
void *p3 = el_malloc(156);
printf("MALLOC 3\n"); el_print_stats(); printf("\n");
printf("POINTERS\n");
print_ptr("p3",p3);
print_ptr("p2",p2);
print_ptr("p1",p1);
printf("\n");
void *p4 = el_malloc(22);
void *p5 = el_malloc(64);
printf("MALLOC 5\n"); el_print_stats(); printf("\n");
printf("POINTERS\n");
print_ptr("p5",p5);
print_ptr("p4",p4);
print_ptr("p3",p3);
print_ptr("p2",p2);
print_ptr("p1",p1);
printf("\n");
el_free(p1);
printf("FREE 1\n"); el_print_stats(); printf("\n");
el_free(p3);
printf("FREE 3\n"); el_print_stats(); printf("\n");
p3 = el_malloc(32);
p1 = el_malloc(200);
printf("ALLOC 3,1 AGAIN\n"); el_print_stats(); printf("\n");
printf("POINTERS\n");
print_ptr("p1",p1);
print_ptr("p3",p3);
print_ptr("p5",p5);
print_ptr("p4",p4);
print_ptr("p2",p2);
printf("\n");
el_free(p1);
printf("FREE'D 1\n"); el_print_stats(); printf("\n");
el_free(p2);
printf("FREE'D 2\n"); el_print_stats(); printf("\n");
p1 = el_malloc(3438);
p2 = el_malloc(1024);
printf("P2 FAILS\n");
printf("POINTERS\n");
print_ptr("p1",p1);
print_ptr("p3",p3);
print_ptr("p5",p5);
print_ptr("p4",p4);
print_ptr("p2",p2);
el_print_stats(); printf("\n");
el_append_pages_to_heap(3);
printf("APPENDED PAGES\n"); el_print_stats(); printf("\n");
p2 = el_malloc(1024);
printf("P2 SUCCEEDS\n");
printf("POINTERS\n");
print_ptr("p1",p1);
print_ptr("p3",p3);
print_ptr("p5",p5);
print_ptr("p4",p4);
print_ptr("p2",p2);
el_print_stats(); printf("\n");
el_free(p1);
el_free(p2);
el_free(p3);
el_free(p4);
el_free(p5);
printf("FREE'D 1-5\n"); el_print_stats(); printf("\n");
el_cleanup();
return 0;
}
Output of El Malloc Demo
EL_BLOCK_OVERHEAD: 40
INITIAL
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000001000
total_bytes: 4096
AVAILABLE LIST: {length: 1 bytes: 4096}
[ 0] head @ 0x612000000000 {state: a size: 4056}
USED LIST: {length: 0 bytes: 0}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 4056 (total: 0x1000)
prev: 0x610000000018
next: 0x610000000038
user: 0x612000000020
foot: 0x612000000ff8
foot->size: 4056
MALLOC 3
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000001000
total_bytes: 4096
AVAILABLE LIST: {length: 1 bytes: 3644}
[ 0] head @ 0x6120000001c4 {state: a size: 3604}
USED LIST: {length: 3 bytes: 452}
[ 0] head @ 0x612000000100 {state: u size: 156}
[ 1] head @ 0x6120000000a8 {state: u size: 48}
[ 2] head @ 0x612000000000 {state: u size: 128}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: u
size: 128 (total: 0xa8)
prev: 0x6120000000a8
next: 0x610000000098
user: 0x612000000020
foot: 0x6120000000a0
foot->size: 128
[ 1] @ 0x6120000000a8
state: u
size: 48 (total: 0x58)
prev: 0x612000000100
next: 0x612000000000
user: 0x6120000000c8
foot: 0x6120000000f8
foot->size: 48
[ 2] @ 0x612000000100
state: u
size: 156 (total: 0xc4)
prev: 0x610000000078
next: 0x6120000000a8
user: 0x612000000120
foot: 0x6120000001bc
foot->size: 156
[ 3] @ 0x6120000001c4
state: a
size: 3604 (total: 0xe3c)
prev: 0x610000000018
next: 0x610000000038
user: 0x6120000001e4
foot: 0x612000000ff8
foot->size: 3604
POINTERS
p3: 0x612000000120
p2: 0x6120000000c8
p1: 0x612000000020
MALLOC 5
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000001000
total_bytes: 4096
AVAILABLE LIST: {length: 1 bytes: 3478}
[ 0] head @ 0x61200000026a {state: a size: 3438}
USED LIST: {length: 5 bytes: 618}
[ 0] head @ 0x612000000202 {state: u size: 64}
[ 1] head @ 0x6120000001c4 {state: u size: 22}
[ 2] head @ 0x612000000100 {state: u size: 156}
[ 3] head @ 0x6120000000a8 {state: u size: 48}
[ 4] head @ 0x612000000000 {state: u size: 128}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: u
size: 128 (total: 0xa8)
prev: 0x6120000000a8
next: 0x610000000098
user: 0x612000000020
foot: 0x6120000000a0
foot->size: 128
[ 1] @ 0x6120000000a8
state: u
size: 48 (total: 0x58)
prev: 0x612000000100
next: 0x612000000000
user: 0x6120000000c8
foot: 0x6120000000f8
foot->size: 48
[ 2] @ 0x612000000100
state: u
size: 156 (total: 0xc4)
prev: 0x6120000001c4
next: 0x6120000000a8
user: 0x612000000120
foot: 0x6120000001bc
foot->size: 156
[ 3] @ 0x6120000001c4
state: u
size: 22 (total: 0x3e)
prev: 0x612000000202
next: 0x612000000100
user: 0x6120000001e4
foot: 0x6120000001fa
foot->size: 22
[ 4] @ 0x612000000202
state: u
size: 64 (total: 0x68)
prev: 0x610000000078
next: 0x6120000001c4
user: 0x612000000222
foot: 0x612000000262
foot->size: 64
[ 5] @ 0x61200000026a
state: a
size: 3438 (total: 0xd96)
prev: 0x610000000018
next: 0x610000000038
user: 0x61200000028a
foot: 0x612000000ff8
foot->size: 3438
POINTERS
p5: 0x612000000222
p4: 0x6120000001e4
p3: 0x612000000120
p2: 0x6120000000c8
p1: 0x612000000020
FREE 1
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000001000
total_bytes: 4096
AVAILABLE LIST: {length: 2 bytes: 3646}
[ 0] head @ 0x612000000000 {state: a size: 128}
[ 1] head @ 0x61200000026a {state: a size: 3438}
USED LIST: {length: 4 bytes: 450}
[ 0] head @ 0x612000000202 {state: u size: 64}
[ 1] head @ 0x6120000001c4 {state: u size: 22}
[ 2] head @ 0x612000000100 {state: u size: 156}
[ 3] head @ 0x6120000000a8 {state: u size: 48}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 128 (total: 0xa8)
prev: 0x610000000018
next: 0x61200000026a
user: 0x612000000020
foot: 0x6120000000a0
foot->size: 128
[ 1] @ 0x6120000000a8
state: u
size: 48 (total: 0x58)
prev: 0x612000000100
next: 0x610000000098
user: 0x6120000000c8
foot: 0x6120000000f8
foot->size: 48
[ 2] @ 0x612000000100
state: u
size: 156 (total: 0xc4)
prev: 0x6120000001c4
next: 0x6120000000a8
user: 0x612000000120
foot: 0x6120000001bc
foot->size: 156
[ 3] @ 0x6120000001c4
state: u
size: 22 (total: 0x3e)
prev: 0x612000000202
next: 0x612000000100
user: 0x6120000001e4
foot: 0x6120000001fa
foot->size: 22
[ 4] @ 0x612000000202
state: u
size: 64 (total: 0x68)
prev: 0x610000000078
next: 0x6120000001c4
user: 0x612000000222
foot: 0x612000000262
foot->size: 64
[ 5] @ 0x61200000026a
state: a
size: 3438 (total: 0xd96)
prev: 0x612000000000
next: 0x610000000038
user: 0x61200000028a
foot: 0x612000000ff8
foot->size: 3438
FREE 3
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000001000
total_bytes: 4096
AVAILABLE LIST: {length: 3 bytes: 3842}
[ 0] head @ 0x612000000100 {state: a size: 156}
[ 1] head @ 0x612000000000 {state: a size: 128}
[ 2] head @ 0x61200000026a {state: a size: 3438}
USED LIST: {length: 3 bytes: 254}
[ 0] head @ 0x612000000202 {state: u size: 64}
[ 1] head @ 0x6120000001c4 {state: u size: 22}
[ 2] head @ 0x6120000000a8 {state: u size: 48}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 128 (total: 0xa8)
prev: 0x612000000100
next: 0x61200000026a
user: 0x612000000020
foot: 0x6120000000a0
foot->size: 128
[ 1] @ 0x6120000000a8
state: u
size: 48 (total: 0x58)
prev: 0x6120000001c4
next: 0x610000000098
user: 0x6120000000c8
foot: 0x6120000000f8
foot->size: 48
[ 2] @ 0x612000000100
state: a
size: 156 (total: 0xc4)
prev: 0x610000000018
next: 0x612000000000
user: 0x612000000120
foot: 0x6120000001bc
foot->size: 156
[ 3] @ 0x6120000001c4
state: u
size: 22 (total: 0x3e)
prev: 0x612000000202
next: 0x6120000000a8
user: 0x6120000001e4
foot: 0x6120000001fa
foot->size: 22
[ 4] @ 0x612000000202
state: u
size: 64 (total: 0x68)
prev: 0x610000000078
next: 0x6120000001c4
user: 0x612000000222
foot: 0x612000000262
foot->size: 64
[ 5] @ 0x61200000026a
state: a
size: 3438 (total: 0xd96)
prev: 0x612000000000
next: 0x610000000038
user: 0x61200000028a
foot: 0x612000000ff8
foot->size: 3438
ALLOC 3,1 AGAIN
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000001000
total_bytes: 4096
AVAILABLE LIST: {length: 3 bytes: 3530}
[ 0] head @ 0x61200000035a {state: a size: 3198}
[ 1] head @ 0x612000000148 {state: a size: 84}
[ 2] head @ 0x612000000000 {state: a size: 128}
USED LIST: {length: 5 bytes: 566}
[ 0] head @ 0x61200000026a {state: u size: 200}
[ 1] head @ 0x612000000100 {state: u size: 32}
[ 2] head @ 0x612000000202 {state: u size: 64}
[ 3] head @ 0x6120000001c4 {state: u size: 22}
[ 4] head @ 0x6120000000a8 {state: u size: 48}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 128 (total: 0xa8)
prev: 0x612000000148
next: 0x610000000038
user: 0x612000000020
foot: 0x6120000000a0
foot->size: 128
[ 1] @ 0x6120000000a8
state: u
size: 48 (total: 0x58)
prev: 0x6120000001c4
next: 0x610000000098
user: 0x6120000000c8
foot: 0x6120000000f8
foot->size: 48
[ 2] @ 0x612000000100
state: u
size: 32 (total: 0x48)
prev: 0x61200000026a
next: 0x612000000202
user: 0x612000000120
foot: 0x612000000140
foot->size: 32
[ 3] @ 0x612000000148
state: a
size: 84 (total: 0x7c)
prev: 0x61200000035a
next: 0x612000000000
user: 0x612000000168
foot: 0x6120000001bc
foot->size: 84
[ 4] @ 0x6120000001c4
state: u
size: 22 (total: 0x3e)
prev: 0x612000000202
next: 0x6120000000a8
user: 0x6120000001e4
foot: 0x6120000001fa
foot->size: 22
[ 5] @ 0x612000000202
state: u
size: 64 (total: 0x68)
prev: 0x612000000100
next: 0x6120000001c4
user: 0x612000000222
foot: 0x612000000262
foot->size: 64
[ 6] @ 0x61200000026a
state: u
size: 200 (total: 0xf0)
prev: 0x610000000078
next: 0x612000000100
user: 0x61200000028a
foot: 0x612000000352
foot->size: 200
[ 7] @ 0x61200000035a
state: a
size: 3198 (total: 0xca6)
prev: 0x610000000018
next: 0x612000000148
user: 0x61200000037a
foot: 0x612000000ff8
foot->size: 3198
POINTERS
p1: 0x61200000028a
p3: 0x612000000120
p5: 0x612000000222
p4: 0x6120000001e4
p2: 0x6120000000c8
FREE'D 1
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000001000
total_bytes: 4096
AVAILABLE LIST: {length: 3 bytes: 3770}
[ 0] head @ 0x61200000026a {state: a size: 3438}
[ 1] head @ 0x612000000148 {state: a size: 84}
[ 2] head @ 0x612000000000 {state: a size: 128}
USED LIST: {length: 4 bytes: 326}
[ 0] head @ 0x612000000100 {state: u size: 32}
[ 1] head @ 0x612000000202 {state: u size: 64}
[ 2] head @ 0x6120000001c4 {state: u size: 22}
[ 3] head @ 0x6120000000a8 {state: u size: 48}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 128 (total: 0xa8)
prev: 0x612000000148
next: 0x610000000038
user: 0x612000000020
foot: 0x6120000000a0
foot->size: 128
[ 1] @ 0x6120000000a8
state: u
size: 48 (total: 0x58)
prev: 0x6120000001c4
next: 0x610000000098
user: 0x6120000000c8
foot: 0x6120000000f8
foot->size: 48
[ 2] @ 0x612000000100
state: u
size: 32 (total: 0x48)
prev: 0x610000000078
next: 0x612000000202
user: 0x612000000120
foot: 0x612000000140
foot->size: 32
[ 3] @ 0x612000000148
state: a
size: 84 (total: 0x7c)
prev: 0x61200000026a
next: 0x612000000000
user: 0x612000000168
foot: 0x6120000001bc
foot->size: 84
[ 4] @ 0x6120000001c4
state: u
size: 22 (total: 0x3e)
prev: 0x612000000202
next: 0x6120000000a8
user: 0x6120000001e4
foot: 0x6120000001fa
foot->size: 22
[ 5] @ 0x612000000202
state: u
size: 64 (total: 0x68)
prev: 0x612000000100
next: 0x6120000001c4
user: 0x612000000222
foot: 0x612000000262
foot->size: 64
[ 6] @ 0x61200000026a
state: a
size: 3438 (total: 0xd96)
prev: 0x610000000018
next: 0x612000000148
user: 0x61200000028a
foot: 0x612000000ff8
foot->size: 3438
FREE'D 2
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000001000
total_bytes: 4096
AVAILABLE LIST: {length: 3 bytes: 3858}
[ 0] head @ 0x612000000000 {state: a size: 216}
[ 1] head @ 0x61200000026a {state: a size: 3438}
[ 2] head @ 0x612000000148 {state: a size: 84}
USED LIST: {length: 3 bytes: 238}
[ 0] head @ 0x612000000100 {state: u size: 32}
[ 1] head @ 0x612000000202 {state: u size: 64}
[ 2] head @ 0x6120000001c4 {state: u size: 22}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 216 (total: 0x100)
prev: 0x610000000018
next: 0x61200000026a
user: 0x612000000020
foot: 0x6120000000f8
foot->size: 216
[ 1] @ 0x612000000100
state: u
size: 32 (total: 0x48)
prev: 0x610000000078
next: 0x612000000202
user: 0x612000000120
foot: 0x612000000140
foot->size: 32
[ 2] @ 0x612000000148
state: a
size: 84 (total: 0x7c)
prev: 0x61200000026a
next: 0x610000000038
user: 0x612000000168
foot: 0x6120000001bc
foot->size: 84
[ 3] @ 0x6120000001c4
state: u
size: 22 (total: 0x3e)
prev: 0x612000000202
next: 0x610000000098
user: 0x6120000001e4
foot: 0x6120000001fa
foot->size: 22
[ 4] @ 0x612000000202
state: u
size: 64 (total: 0x68)
prev: 0x612000000100
next: 0x6120000001c4
user: 0x612000000222
foot: 0x612000000262
foot->size: 64
[ 5] @ 0x61200000026a
state: a
size: 3438 (total: 0xd96)
prev: 0x612000000000
next: 0x612000000148
user: 0x61200000028a
foot: 0x612000000ff8
foot->size: 3438
P2 FAILS
POINTERS
p1: 0x61200000028a
p3: 0x612000000120
p5: 0x612000000222
p4: 0x6120000001e4
p2: (nil)
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000001000
total_bytes: 4096
AVAILABLE LIST: {length: 2 bytes: 380}
[ 0] head @ 0x612000000000 {state: a size: 216}
[ 1] head @ 0x612000000148 {state: a size: 84}
USED LIST: {length: 4 bytes: 3716}
[ 0] head @ 0x61200000026a {state: u size: 3438}
[ 1] head @ 0x612000000100 {state: u size: 32}
[ 2] head @ 0x612000000202 {state: u size: 64}
[ 3] head @ 0x6120000001c4 {state: u size: 22}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 216 (total: 0x100)
prev: 0x610000000018
next: 0x612000000148
user: 0x612000000020
foot: 0x6120000000f8
foot->size: 216
[ 1] @ 0x612000000100
state: u
size: 32 (total: 0x48)
prev: 0x61200000026a
next: 0x612000000202
user: 0x612000000120
foot: 0x612000000140
foot->size: 32
[ 2] @ 0x612000000148
state: a
size: 84 (total: 0x7c)
prev: 0x612000000000
next: 0x610000000038
user: 0x612000000168
foot: 0x6120000001bc
foot->size: 84
[ 3] @ 0x6120000001c4
state: u
size: 22 (total: 0x3e)
prev: 0x612000000202
next: 0x610000000098
user: 0x6120000001e4
foot: 0x6120000001fa
foot->size: 22
[ 4] @ 0x612000000202
state: u
size: 64 (total: 0x68)
prev: 0x612000000100
next: 0x6120000001c4
user: 0x612000000222
foot: 0x612000000262
foot->size: 64
[ 5] @ 0x61200000026a
state: u
size: 3438 (total: 0xd96)
prev: 0x610000000078
next: 0x612000000100
user: 0x61200000028a
foot: 0x612000000ff8
foot->size: 3438
APPENDED PAGES
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000004000
total_bytes: 16384
AVAILABLE LIST: {length: 3 bytes: 12668}
[ 0] head @ 0x612000001000 {state: a size: 12248}
[ 1] head @ 0x612000000000 {state: a size: 216}
[ 2] head @ 0x612000000148 {state: a size: 84}
USED LIST: {length: 4 bytes: 3716}
[ 0] head @ 0x61200000026a {state: u size: 3438}
[ 1] head @ 0x612000000100 {state: u size: 32}
[ 2] head @ 0x612000000202 {state: u size: 64}
[ 3] head @ 0x6120000001c4 {state: u size: 22}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 216 (total: 0x100)
prev: 0x612000001000
next: 0x612000000148
user: 0x612000000020
foot: 0x6120000000f8
foot->size: 216
[ 1] @ 0x612000000100
state: u
size: 32 (total: 0x48)
prev: 0x61200000026a
next: 0x612000000202
user: 0x612000000120
foot: 0x612000000140
foot->size: 32
[ 2] @ 0x612000000148
state: a
size: 84 (total: 0x7c)
prev: 0x612000000000
next: 0x610000000038
user: 0x612000000168
foot: 0x6120000001bc
foot->size: 84
[ 3] @ 0x6120000001c4
state: u
size: 22 (total: 0x3e)
prev: 0x612000000202
next: 0x610000000098
user: 0x6120000001e4
foot: 0x6120000001fa
foot->size: 22
[ 4] @ 0x612000000202
state: u
size: 64 (total: 0x68)
prev: 0x612000000100
next: 0x6120000001c4
user: 0x612000000222
foot: 0x612000000262
foot->size: 64
[ 5] @ 0x61200000026a
state: u
size: 3438 (total: 0xd96)
prev: 0x610000000078
next: 0x612000000100
user: 0x61200000028a
foot: 0x612000000ff8
foot->size: 3438
[ 6] @ 0x612000001000
state: a
size: 12248 (total: 0x3000)
prev: 0x610000000018
next: 0x612000000000
user: 0x612000001020
foot: 0x612000003ff8
foot->size: 12248
P2 SUCCEEDS
POINTERS
p1: 0x61200000028a
p3: 0x612000000120
p5: 0x612000000222
p4: 0x6120000001e4
p2: 0x612000001020
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000004000
total_bytes: 16384
AVAILABLE LIST: {length: 3 bytes: 11604}
[ 0] head @ 0x612000001428 {state: a size: 11184}
[ 1] head @ 0x612000000000 {state: a size: 216}
[ 2] head @ 0x612000000148 {state: a size: 84}
USED LIST: {length: 5 bytes: 4780}
[ 0] head @ 0x612000001000 {state: u size: 1024}
[ 1] head @ 0x61200000026a {state: u size: 3438}
[ 2] head @ 0x612000000100 {state: u size: 32}
[ 3] head @ 0x612000000202 {state: u size: 64}
[ 4] head @ 0x6120000001c4 {state: u size: 22}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 216 (total: 0x100)
prev: 0x612000001428
next: 0x612000000148
user: 0x612000000020
foot: 0x6120000000f8
foot->size: 216
[ 1] @ 0x612000000100
state: u
size: 32 (total: 0x48)
prev: 0x61200000026a
next: 0x612000000202
user: 0x612000000120
foot: 0x612000000140
foot->size: 32
[ 2] @ 0x612000000148
state: a
size: 84 (total: 0x7c)
prev: 0x612000000000
next: 0x610000000038
user: 0x612000000168
foot: 0x6120000001bc
foot->size: 84
[ 3] @ 0x6120000001c4
state: u
size: 22 (total: 0x3e)
prev: 0x612000000202
next: 0x610000000098
user: 0x6120000001e4
foot: 0x6120000001fa
foot->size: 22
[ 4] @ 0x612000000202
state: u
size: 64 (total: 0x68)
prev: 0x612000000100
next: 0x6120000001c4
user: 0x612000000222
foot: 0x612000000262
foot->size: 64
[ 5] @ 0x61200000026a
state: u
size: 3438 (total: 0xd96)
prev: 0x612000001000
next: 0x612000000100
user: 0x61200000028a
foot: 0x612000000ff8
foot->size: 3438
[ 6] @ 0x612000001000
state: u
size: 1024 (total: 0x428)
prev: 0x610000000078
next: 0x61200000026a
user: 0x612000001020
foot: 0x612000001420
foot->size: 1024
[ 7] @ 0x612000001428
state: a
size: 11184 (total: 0x2bd8)
prev: 0x610000000018
next: 0x612000000000
user: 0x612000001448
foot: 0x612000003ff8
foot->size: 11184
FREE'D 1-5
HEAP STATS (overhead per node: 40)
heap_start: 0x612000000000
heap_end: 0x612000004000
total_bytes: 16384
AVAILABLE LIST: {length: 1 bytes: 16384}
[ 0] head @ 0x612000000000 {state: a size: 16344}
USED LIST: {length: 0 bytes: 0}
HEAP BLOCKS:
[ 0] @ 0x612000000000
state: a
size: 16344 (total: 0x4000)
prev: 0x610000000018
next: 0x610000000038
user: 0x612000000020
foot: 0x612000003ff8
foot->size: 16344
3.12 Grading Criteria for Problem 1 grading 45
| Weight | Criteria |
|---|---|
| Automated Tests | |
| 20 | make test-prob1 runs tests for correctness with Valgrind enabled |
| 20 tests, 1 point per test | |
| Manual Inspection | |
| 4 | Code Style: Functions adhere to CMSC 216 C Coding Style Guide which dictates reasonable indentation, commenting, consistency of curly usage, etc. |
| 3 | el_get_header() and el_block_below() |
| Use of provided macros for pointer arithmetic | |
Correct use of sizeof() operator to account for sizes |
|
el_block_below() checks for beginning of heap and returns NULL |
|
| 3 | el_add_block_front() and el_remove_block() |
| Sensible use of pointers prev/next to link/unlink nodes efficiently; no looping used | |
| Correct updating of list length and bytes | |
Accounts for EL_BLOCK_OVERHEAD when updating bytes |
|
| 3 | el_split_block() |
Use of el_get_foot() to obtain footers for updating size |
|
| Checks to determine if block is large enough to be split; returns NULL if not | |
| Clear evidence of placing a new header and footer for new block when splitting | |
Accounting for overhead EL_BLOCK_OVERHEAD when calculating new size |
|
| 3 | el_malloc() |
Use of el_find_first_avail() to locate a node to split |
|
Use of el_split_block() to split block into two |
|
| Clear state change of split blocks to Used and Available | |
| Clear movement of lower split blocks to front of Used List | |
| Clear movement of upper split blocks to front of Available lists | |
| Use of pointer arithmetic macros to computer user address | |
| 3 | el_merge_block_with_above() |
NULL checks for argument and block above which result in no changes |
|
Clear checks of whether both blocks are EL_AVAILABLE |
|
Use of el_block_above() to find block above |
|
| Clear updates to size of lower block and higher foot | |
| Movement of blocks out of available list and merged block to front | |
| 3 | el_free() |
Error checking that block is EL_USED |
|
| Movement of block from used to available list | |
| Attempts to merge block with blocks above and below it | |
| 3 | el_append_pages_to_heap() |
Makes use of mmap() to map in additional pages of virtual memory |
|
Checks mmap() for failures and prints appropriate error messages |
|
| Maps new heap space to current heap end to create a contiguous heap | |
| Creates new available block for new space and attempts to merge with existing available blocks | |
| 45 | Problem Total |
4 Problem 2: Matrix Column Normalization
The structure of this problem is to optimize a baseline version of an existing function. Normally this should be done only when there is good cause to do so: correctly functioning code is hard enough to create and so long as it is "fast enough" there is little need to optimize. As preeminent computer scientist Donald Knuth is widely quoted:
"Premature optimization is the root of all evil."
Few folks know as well the context of that quotation. When he originally stated it, it, Knuth caveats the oft cited portion and advocates that there are times when it is important to focus on speeding up code:
"We should forget about small efficiencies, say about 97% of the time… Yet we should not pass up our opportunities in that critical 3%."
Optimizing code is an important skill that require practice to master as there are many forms of optimizations may take. This problem will present opportunities to speed up code in two ways:
- Optimize the efficiency of memory access to favor CPU caches
- Utilize multiple threads to achieve some parallel execution.
While these are not the only kinds of optimizations, they are significant enough to merit consideration in a programming project.
4.1 Algorithm Overview
A common problem in statistics and machine learning is to "normalize" numerical data so that disparate data are in a similar range. While normalization can take a wide variety of meanings, here we will use a common statistical definition:
- Normalized data has an average (mean) of 0.0
- Normalized data has a standard deviation of 1.0
Transforming such data is sometimes referred to as "standardizing" it or replacing original values with their "z-scores".
As a quick reference, the average and standard deviation are computed as follows.
double data[len] = {...}; // DATA
double sum = 0.0;
for(int i=0; i<len; i++){
sum += data[i];
}
double avg = sum / len; // AVERAGE
sum = 0.0;
for(int i=0; i<len; i++){
double diff = data[i] - mean;
sum += diff*diff;
}
double std = sqrt(sum / len); // STANDARD DEVIATION
Note that here the "population" standard deviation is computed rather than the "sample" standard deviation.
Another common convention in statistics and machine learning is that data is stored in matrices as follows:
- Each row represents a sample (e.g. a person, object, sale, etc.)
- Each column representing a feature of that sample (e.g. height, weight, age, etc.)
In this setting, it is sensible to normalize columns. Each column of data encodes data that is on a common scale (meters for height, kilograms for weight, years for age, etc) and normalizing an individual column will show how far any sample (person) has an attributes that deviate from the average.
The goal of this problem is to write a version of a colnorm()
function which performs this column normalization operation on a
matrix. The basic computation looks like the following.
1. START mat is a 5x8 matrix
mat = [-6.00 -9.00 1.00 2.00 -6.00 -5.00 6.00 0.00
-5.00 4.00 -3.00 -2.00 2.00 -10.00 -3.00 7.00
7.00 -10.00 -4.00 -7.00 -4.00 9.00 1.00 7.00
3.00 -8.00 -7.00 2.00 8.00 -8.00 3.00 -7.00
-4.00 7.00 -8.00 -4.00 0.00 -3.00 6.00 8.00]
2. COMPUTE average (avg) and standard deviation (std) vector for each column
avg = [-1.00 -3.20 -4.20 -1.80 0.00 -3.40 2.60 3.00]
std = [ 5.70 8.04 3.56 3.90 5.48 7.43 3.78 6.44]
3. MODIFY mat by normalizing each element according to column avg/std
mat = [
(-6+1.00)/5.70 ( -9+3.20)/8.04 ( 1+4.20)/3.56 ( 2+1.80)/3.90 (-6-0.00)/5.48 ( -5+3.40)/7.43 ( 6-2.60)/3.78 ( 0-3.00)/6.44
(-5+1.00)/5.70 ( 4+3.20)/8.04 (-3+4.20)/3.56 (-2+1.80)/3.90 ( 2-0.00)/5.48 (-10+3.40)/7.43 (-3-2.60)/3.78 ( 7-3.00)/6.44
( 7+1.00)/5.70 (-10+3.20)/8.04 (-4+4.20)/3.56 (-7+1.80)/3.90 (-4-0.00)/5.48 ( 9+3.40)/7.43 ( 1-2.60)/3.78 ( 7-3.00)/6.44
( 3+1.00)/5.70 ( -8+3.20)/8.04 (-7+4.20)/3.56 ( 2+1.80)/3.90 ( 8-0.00)/5.48 ( -8+3.40)/7.43 ( 3-2.60)/3.78 (-7-3.00)/6.44
(-4+1.00)/5.70 ( 7+3.20)/8.04 (-8+4.20)/3.56 (-4+1.80)/3.90 ( 0-0.00)/5.48 ( -3+3.40)/7.43 ( 6-2.60)/3.78 ( 8-3.00)/6.44
]
4. FINISH: Each column of mat has average 0.0 and standard deviation 1.0
mat = [-0.88 -0.72 1.46 0.97 -1.10 -0.22 0.90 -0.47
-0.70 0.90 0.34 -0.05 0.37 -0.89 -1.48 0.62
1.40 -0.85 0.06 -1.33 -0.73 1.67 -0.42 0.62
0.70 -0.60 -0.79 0.97 1.46 -0.62 0.11 -1.55
-0.53 1.27 -1.07 -0.56 0.00 0.05 0.90 0.78]
avg = [ 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]
std = [ 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00]
avg/std are NOT changed, only shown here for reference
A function is provided in colnorm_base.c that normalizes a matrix in
a naive fashion. The "natural" approach is used which iterates down
each column to compute its sum which is then used to determine the
column average. After this, the column standard deviation is computed
again by working down a column. Finally, each element of the column is
visited to normalize it using the computer avg/std. This process is
repeated for each column.
As you survey the code, note the use of various convenience macros
VSET(vec,i,x) / VGET(vec,i)to set/get elements from a vector structMSET(mat,i,j,x) / MGET(mat,i,j)to set/get elements from a matrix struct
// colnorm_base.c: baseline version of column normalization
#include "colnorm.h"
// Baseline version which normalizes each column of a matrix to have
// average 0.0 and standard deviation 1.0. During the computation, the
// vectors avg/std are set to the average and standard deviation of
// the original matrix. Elements in mat are modified so that each
// column is normalized.
int colnorm_BASE_1(matrix_t mat, vector_t avg, vector_t std) {
// for(int i=0; i<avg.len; i++){ // initialize avg/std to all 0s
// VSET(avg, i, 0.0); // not necessary here but needed
// VSET(std, i, 0.0); // for some algorithms; memset()
// } // may also be used here
for(int j=0; j<mat.cols; j++){ // for each column in matrix
double sum_j = 0.0; // PASS 1: Compute column average
for(int i=0; i<mat.rows; i++){
sum_j += MGET(mat,i,j);
}
double avg_j = sum_j / mat.rows;
VSET(avg,j,avg_j);
sum_j = 0.0;
for(int i=0; i<mat.rows; i++){ // PASS 2: Compute standard deviation
double diff = MGET(mat,i,j) - avg_j;
sum_j += diff*diff;
};
double std_j = sqrt(sum_j / mat.rows);
VSET(std,j,std_j);
for(int i=0; i<mat.rows; i++){ // PASS 3: Normalize matrix column
double mij = MGET(mat,i,j);
mij = (mij - avg_j) / std_j;
MSET(mat,i,j,mij);
}
}
return 0;
}
While this algorithm is a direct translation of how humans would visually perform the calculation for small matrices, it is unfortunately fairly slow when executing on most modern computing systems.
4.2 Optimize Column Normalization
The purpose of this problem is to write colnorm_OPTM() which is a
faster version of the provided colnorm_BASE() .
Write your code in the file colnorm_optm.c.
Keep the following things in mind.
- You will need to acquaint yourself with the functions and types
related to matrices and vectors provided in the
colnorm.hand demonstrated in the baseline function. Understanding the layout of the matrix in memory is essential to unlocking performance. - The goal of
colnorm_OPTM()is to exceed the performance ofcolnorm_BASE()by as much as possible. - To achieve this goal, several optimizations must be implemented and suggestions are given in a later section.
- There is one additional parameter to the optimized function:
colnorm_OPTM(mat,avg,std,thread_count). This indicates the number of threads that should be used during the computation. - Part of your grade will be based on the speed of the optimized code
on
grace.umd.edu. The main routinecolnorm_benchmark.cwill be used for this.
Some details are provided in subsequent sections.
4.3 Evaluation on Grace
The file colnorm_benchmark.c provides a benchmark for the speed of
the algorithms. It will be used by graders to evaluate the submitted
code and should be used during development to gauge performance
improvements. It runs both the Baseline and Optimized versions
(from colnorm_base.c and colnorm_optm.c respectively) and compares
their performance.
While the benchmark runs on any machine, it is specifically tailored to run on the following machines:
grace3.umd.edu grace5.umd.edu grace7.umd.edu grace9.umd.edu
These Grace nodes have a reasonably large cache and fast processor
while other Grace nodes have slower, older processors. The scoring
present in colnorm_benchmark.c is "tuned" to these machines and will
likely report incorrect results on other machines. Test your
performance on these nodes so that no unexpected results occur after
submission.
While on one Grace node, you may log into another Grace node in a terminal via SSH as shown below.
grace8>> ssh grace3 Password: ...... Duo Authenticate: 1 Duo Push : OK! grace3>>
The output of the colnorm_benchmark is shown below.
SIZE: the size of the matrix being used. The benchmark always uses square matricesBASE: the time it takes forcolnorm_BASE()to complete.T: number of threads used for runningcolnorm_OPTM()OPTM: the time it takes forcolnorm_OPTM()to complete.SPDUP: the speedup ofcolnorm_OPTM()overcolnorm_BASE()which isBASE / OPTM.POINT: points earned on this run according to the following code:double points = log(speedup_OPTM) / log(2.0);
This scheme means that unless actual optimizations are implemented, 0 points will be scored. Each speedup by a factor of 2X earns 1 point: finishing in half the time (2X speedup) of the Baseline earns 1.0 points, one quarter of time (4X speedup) earns 2.0 points, 1/8th the time (8X speedup) 3.0 points, and so on.
TOTAL: the running total of points accumulated after running each segment of the benchmark.
Below are several demonstration runs of colnorm_benchmark.
# ###############################################################################
# RUN ON INCORRECT MACHINE (NOT ODD grace nodes), NOTE WARNINGS
>> ssh grace.umd.edu
...
grace4>> ./colnorm_benchmark
WARNING: expected host like 'grace9.umd.edu' but got host 'grace4.umd.edu'
WARNING: ensure you are on an ODD grace node
WARNING: timing results / scoring will not reflect actual scoring
WARNING: run on one of the following hosts for accurate results
WARNING: grace3.umd.edu
WARNING: grace5.umd.edu
WARNING: grace7.umd.edu
WARNING: grace9.umd.edu
WARNING: while on grace, try `ssh grace5` to log into a specifc node
==== Matrix Column Normalization Benchmark Version 1 ====
------ Tuned for ODD grace.umd.edu machines -----
Running with REPEATS: 2 and WARMUP: 1
Running with 4 sizes and 4 thread_counts (max 4)
ROWS COLS BASE T OPTM SPDUP POINT TOTAL
1111 2223 0.028 1 0.022 1.29 0.37 0.37
2 0.021 1.30 0.38 0.75
3 0.021 1.31 0.39 1.14
4 0.021 1.32 0.40 1.54
2049 4098 0.098 1 0.076 1.29 0.37 1.91
2 0.074 1.31 0.39 2.30
3 0.076 1.29 0.37 2.67
4 0.075 1.30 0.38 3.05
4099 8197 0.330 1 0.297 1.11 0.15 3.21
2 0.296 1.11 0.15 3.36
3 0.293 1.12 0.17 3.53
4 0.294 1.12 0.17 3.70
6001 12003 0.828 1 0.623 1.33 0.41 4.11
2 0.630 1.31 0.39 4.50
3 0.623 1.33 0.41 4.91
4 0.622 1.33 0.41 5.33
RAW POINTS: 5.33
TOTAL POINTS: 5 / 35
WARNING: expected host like 'grace9.umd.edu' but got host 'grace4.umd.edu'
WARNING: ensure you are on an ODD grace node
WARNING: timing results / scoring will not reflect actual scoring
WARNING: run on one of the following hosts for accurate results
WARNING: grace3.umd.edu
WARNING: grace5.umd.edu
WARNING: grace7.umd.edu
WARNING: grace9.umd.edu
WARNING: while on grace, try `ssh grace5` to log into a specifc node
# ###############################################################################
# PARTIAL CREDIT RUN
>> ssh grace.umd.edu
...
grace4>> ssh grace3
...
grace3>> ./colnorm_benchmark
==== Matrix Column Normalization Benchmark Version 1 ====
------ Tuned for ODD grace.umd.edu machines -----
Running with REPEATS: 2 and WARMUP: 1
Running with 4 sizes (max 6001) and 4 thread_counts (max 4)
ROWS COLS BASE T OPTM SPDUP POINT TOTAL
1111 2223 0.029 1 0.022 1.29 0.37 0.37
2 0.022 1.27 0.35 0.72
3 0.022 1.30 0.38 1.10
4 0.022 1.31 0.38 1.48
2049 4098 0.202 1 0.075 2.68 1.42 2.91
2 0.076 2.67 1.42 4.32
3 0.075 2.68 1.42 5.74
4 0.076 2.66 1.41 7.16
4099 8197 2.566 1 0.296 8.65 3.11 10.27
2 0.294 8.72 3.12 13.39
3 0.296 8.68 3.12 16.51
4 0.295 8.69 3.12 19.63
6001 12003 5.801 1 0.630 9.20 3.20 22.83
2 0.634 9.15 3.19 26.03
3 0.629 9.23 3.21 29.23
4 0.630 9.21 3.20 32.43
RAW POINTS: 32.43
TOTAL POINTS: 32 / 35
# ###############################################################################
# FULL CREDIT RUN
>> ssh grace.umd.edu
...
grace4>> ssh grace3
...
grace3>> ./colnorm_benchmark
==== Matrix Column Normalization Benchmark Version 1 ====
------ Tuned for ODD grace.umd.edu machines -----
Running with REPEATS: 2 and WARMUP: 1
Running with 4 sizes (max 6001) and 4 thread_counts (max 4)
ROWS COLS BASE T OPTM SPDUP POINT TOTAL
1111 2223 0.031 1 0.027 1.16 0.21 0.21
2 0.024 1.30 0.38 0.60
3 0.022 1.41 0.49 1.09
4 0.020 1.55 0.63 1.72
2049 4098 0.200 1 0.075 2.67 1.42 3.14
2 0.039 5.14 2.36 5.50
3 0.054 3.68 1.88 7.39
4 0.048 4.14 2.05 9.44
4099 8197 2.561 1 0.303 8.47 3.08 12.52
2 0.151 16.97 4.08 16.60
3 0.213 12.01 3.59 20.19
4 0.162 15.82 3.98 24.17
6001 12003 5.769 1 0.647 8.92 3.16 27.33
2 0.329 17.54 4.13 31.46
3 0.460 12.54 3.65 35.11
4 0.351 16.45 4.04 39.15
RAW POINTS: 39.15
TOTAL POINTS: 35 / 35
Note that it is possible to exceed the score associated with maximal performance (as seen in the RAW POINTS reported) but no more than the final reported points will be given for the performance portion of the problem.
Significantly exceeding the max score may garner some MAKEUP credit: you'll know you earned this as the benchmark will report as much. See the later section for suggestions of potential additional optimizations.
4.4 colnorm_print.c Testing Program
As one works on implementing optimizations in colnorm_OPTM(), bugs
which compute incorrect results are often introduced. To aid in
testing, the colnorm_print() program runs both the BASE and OPTM
versions on the same matrix and shows all results. The matrix size is
determined from the command line and is printed on the screen to
enable hand verification. Examples are below.
Correct Output
Below the output of the optimized version matches the baseline so no entries are marked as erroneous.
>> ./colnorm_print # show usage: pass mat size and thread_count usage: ./colnorm_print <size> <thread_count> >> ./colnorm_print 5 8 1 ==== Matrix Column Normalization Print ==== rows: 5 cols: 8 threads: 1 Matrix: 5 x 8 matrix 0: -6.00 -9.00 1.00 2.00 -6.00 -5.00 6.00 0.00 1: 9.00 6.00 -5.00 4.00 -3.00 -2.00 2.00 -10.00 2: -3.00 7.00 -5.00 4.00 7.00 -10.00 -4.00 -7.00 3: -4.00 9.00 1.00 7.00 -8.00 4.00 3.00 -8.00 4: -7.00 2.00 8.00 -8.00 3.00 -7.00 6.00 -5.00 ========== avg ========== [ i]: BASE OPTM [ 0]: -2.2000 -2.2000 [ 1]: 3.0000 3.0000 [ 2]: 0.0000 0.0000 [ 3]: 1.8000 1.8000 [ 4]: -1.4000 -1.4000 [ 5]: -4.0000 -4.0000 [ 6]: 2.6000 2.6000 [ 7]: -6.0000 -6.0000 ========== std ========== [ i]: BASE OPTM [ 0]: 5.7758 5.7758 [ 1]: 6.4187 6.4187 [ 2]: 4.8166 4.8166 [ 3]: 5.1536 5.1536 [ 4]: 5.6071 5.6071 [ 5]: 4.7749 4.7749 [ 6]: 3.6661 3.6661 [ 7]: 3.4059 3.4059 ========== mat ========== [ i][ j]: BASE OPTM [ 0][ 0]: -0.6579 -0.6579 [ 0][ 1]: -1.8695 -1.8695 [ 0][ 2]: 0.2076 0.2076 [ 0][ 3]: 0.0388 0.0388 [ 0][ 4]: -0.8204 -0.8204 [ 0][ 5]: -0.2094 -0.2094 [ 0][ 6]: 0.9274 0.9274 [ 0][ 7]: 1.7617 1.7617 [ 1][ 0]: 1.9391 1.9391 [ 1][ 1]: 0.4674 0.4674 [ 1][ 2]: -1.0381 -1.0381 [ 1][ 3]: 0.4269 0.4269 [ 1][ 4]: -0.2854 -0.2854 [ 1][ 5]: 0.4189 0.4189 [ 1][ 6]: -0.1637 -0.1637 [ 1][ 7]: -1.1744 -1.1744 [ 2][ 0]: -0.1385 -0.1385 [ 2][ 1]: 0.6232 0.6232 [ 2][ 2]: -1.0381 -1.0381 [ 2][ 3]: 0.4269 0.4269 [ 2][ 4]: 1.4981 1.4981 [ 2][ 5]: -1.2566 -1.2566 [ 2][ 6]: -1.8003 -1.8003 [ 2][ 7]: -0.2936 -0.2936 [ 3][ 0]: -0.3116 -0.3116 [ 3][ 1]: 0.9348 0.9348 [ 3][ 2]: 0.2076 0.2076 [ 3][ 3]: 1.0090 1.0090 [ 3][ 4]: -1.1771 -1.1771 [ 3][ 5]: 1.6754 1.6754 [ 3][ 6]: 0.1091 0.1091 [ 3][ 7]: -0.5872 -0.5872 [ 4][ 0]: -0.8311 -0.8311 [ 4][ 1]: -0.1558 -0.1558 [ 4][ 2]: 1.6609 1.6609 [ 4][ 3]: -1.9016 -1.9016 [ 4][ 4]: 0.7847 0.7847 [ 4][ 5]: -0.6283 -0.6283 [ 4][ 6]: 0.9274 0.9274 [ 4][ 7]: 0.2936 0.2936
Error Output
In this second example, something has gone wrong in the computation
and all non-matching entries computed by colnorm_OPTM() are marked
with *** in avg / std / mat.
>> ./colnorm_print 4 5 2 ==== Matrix Column Normalization Print ==== rows: 4 cols: 5 threads: 2 Matrix: 4 x 5 matrix 0: -6.00 -9.00 1.00 2.00 -6.00 1: -5.00 6.00 0.00 9.00 6.00 2: -5.00 4.00 -3.00 -2.00 2.00 3: -10.00 -3.00 7.00 -5.00 4.00 ========== avg ========== [ i]: BASE OPTM [ 0]: -6.5000 -nan *** [ 1]: -0.5000 -nan *** [ 2]: 1.2500 -nan *** [ 3]: 1.0000 -nan *** [ 4]: 1.5000 -nan *** ========== std ========== [ i]: BASE OPTM [ 0]: 2.0616 -nan *** [ 1]: 5.9372 -nan *** [ 2]: 3.6315 -nan *** [ 3]: 5.2440 -nan *** [ 4]: 4.5552 -nan *** ========== mat ========== [ i][ j]: BASE OPTM [ 0][ 0]: 0.2425 -6.0000 *** [ 0][ 1]: -1.4317 -9.0000 *** [ 0][ 2]: -0.0688 1.0000 *** [ 0][ 3]: 0.1907 2.0000 *** [ 0][ 4]: -1.6465 -6.0000 *** [ 1][ 0]: 0.7276 -5.0000 *** [ 1][ 1]: 1.0948 6.0000 *** [ 1][ 2]: -0.3442 0.0000 *** [ 1][ 3]: 1.5255 9.0000 *** [ 1][ 4]: 0.9879 6.0000 *** [ 2][ 0]: 0.7276 -5.0000 *** [ 2][ 1]: 0.7579 4.0000 *** [ 2][ 2]: -1.1703 -3.0000 *** [ 2][ 3]: -0.5721 -2.0000 *** [ 2][ 4]: 0.1098 2.0000 *** [ 3][ 0]: -1.6977 -10.0000 *** [ 3][ 1]: -0.4211 -3.0000 *** [ 3][ 2]: 1.5834 7.0000 *** [ 3][ 3]: -1.1442 -5.0000 *** [ 3][ 4]: 0.5488 4.0000 ***
4.5 Optimization Suggestions and Documentation
Labs and lectures will cover several kinds of optimizations which are
useful to improve the speed of colnorm_OPTM(). Two optimizations
are required which are:
- Re-ordering memory accesses to be as sequential as possible which favors cache. Unless memory accesses favor cache, it is unlikely that any other optimizations will have much effect.
- Use threads to split up the work of normalization. The problem has a high degree of parallelism in it with many portions that can be computed in worker threads independently from others. Assume that the number of threads to use will be small compared to the size of the matrix. For example, the benchmark uses at most 4 threads and the smallest matrix is 1111 rows by 2223 columns.
In most cases, implementing these two optimizations correctly will yield full performance points. Look for examples in Lecture and Lab to assist you.
Further guidance on use of threads is below.
Division by Rows vs Columns
The matrix must be divided among worker threads. This can be done by assigning a group of columns to each thread or a group of rows. Consider carefully whether to assign groups of rows or columns to threads. Use your knowledge of the memory system to guide your decision as assigning rows vs columns will affect the order that threads may visit memory.
Note as well that the number of threads will be small so that it is likely several hundred or several thousands rows/cols will be assigned dot each thread. This will allow well-written code the have each thread work independently on portions of the matrix in parallel with other threads.
Use of Mutexes
Whenever a thread must access a memory element that other threads
may reference, protect the access to that memory with a
Mutex. Each thread should lock the mutex, make changes to the
data, then unlock the mutex. Failure to do this when altering
shared data such as the Vector avg or Vector std may result in
incorrect results. Try to keep the code between lock/unlock as
short and fast as possible as only one thread can execute it at a
time.
Use of Barriers
Later parts of the computation may require all threads to complete earlier parts. For example, without having the average for a column computed, it is difficult to compute the standard deviation. If multiple threads are cooperating to compute a shared result, all threads must finish their task before any should move ahead. In these cases, a Barrier is useful. Below is a basic code synopsis:
// global variable, may also be a local variable in a struct
pthread_barrier_t barrier;
void main_thread(int thread_count) {
// main thread sets up the barrier
pthread_barrier_init(&barrier, NULL, thread_count);
// main thread creates threads
for(int i=0; i<thread_count; i++){
...;
pthread_create(..., worker, ...);
}
...;
}
void *worker(void *){
// worker threads compute PART A of the computation
...;
// before continuing to PART B, all threads must finish PART A
// use the barrier to wait until
pthread_barrier_wait(barrier);
// all threads now finished with PART A, safe to proceed to part B
// worker threads compute PART B of the computation
...;
// before continuing to PART C, all threads must finish PART B
// use the barrier to wait until
pthread_barrier_wait(barrier);
// all threads now finished with PART B, safe to proceed to part C
// worker threads compute PART C of the computation
...;
}
4.6 Constraints
Use a Mutex
While it may be possible to implement a completely lock-free solution with threads, your implementation MUST use mutexes to coordinate threads as they access shard data in some part of the code. Credit will be deducted if you do not illustrate use of mutexes as one of the course goals for students to demonstrate proficiency with thread coordination.
Avoid Global Variables
In many simple threaded programs, global variables are a convenient way to give worker threads/functions access to shared data. AVOID THIS for full credit. Use "contexts" instead: define a struct type that contains the data necessary for a worker thread to contribute. Then pass this struct to the worker thread on creation. Common elements of such structs are
- A numeric thread id
- A total thread count
- References (structs or pointers) to data for the computation
- Pointers to any shared locks that are needed to coordinate access
- Pointers to any shared barriers that are needed to coordinate access
Lecture and discussion demos will provide some examples of how this might look
Respect Thread Count
The last parameter to the optimized function indicates the maximum
number of threads to use while. During manual inspection, graders will
check code to ensure that no more than the indicated number of worker
threads will be started by the code (e.g. thread_count=1 but 4
worker threads are started). Attempts to violate this will reduce
performance points to 0.
4.7 Additional Optimizations for MAKEUP Credit
Additional optimizations may be performed to further speed up the computations. Some of these are described in Chapter 5 of Bryant/O'Hallaron.
- Replacing repeated memory references with local non-pointer data which will likely be assigned to registers to alleviate slow-down from memory accesses.
- Increasing potential processor pipelining by adjusting the destinations of arithmetic operations.
- Decreasing any unnecessary work such as memory accesses or arithmetic operations. If a computation is performed multiple times, find a way to perform it only once.
- Investigate the ability of GCC to perform vector operations with its Vector Extensions. This is an advanced technique but with some type definitions and pointer casting, you may enable the compiler to generate code which utilizes packed addition, subtraction, multiplication, and division instructions for floating point numbers which can speed up computations immensely.
None of these are required. However, MAKEUP Credit is available for achieving scores that greatly exceed the original baseline version. The benchmark program will check for high scores and give an obvious sign that makeup credit is earned.
4.8 Grading Criteria for Problem 2 grading 55
| Weight | Criteria |
|---|---|
| AUTOMATED TESTS | |
| 10 | No output/memory errors reported make test-prob2 |
| PERFORMANCE EVALUATION | |
| 35 | Performance of colnorm_OPTM() on grace.umd.edu |
As measured by the provided colnorm_benchmark |
|
| Best score of 3 runs done by graders after submission closes | |
| MAKEUP CREDIT can be earned by greatly exceeding the maximum points possible | |
| Credit earned in this way will be obvious based on the output of the benchmark | |
| 10 | MANUAL INSPECTION of colnorm_optm.c |
Effort to optimize memory access pattern in colnorm_OPTM() |
|
Effort to utilize threads in colnorm_OPTM() |
|
| Clear effort to coordinate thread access to shared data using a mutex | |
| Avoids the use of Global Variables in favor of local "contexts" to give threads data they need | |
Respects the thread_count parameter and does not start excess worker threads |
|
Includes timing results from colnorm_benchmark in a commented table at top of file |
|
| Code Style: Functions adhere to CMSC 216 C Coding Style Guide which dictates reasonable indentation, commenting, consistency of curly usage, etc. | |
| Includes comments describing the overall flow of optimized code, intent and purpose of loops. | |
| 55 | Problem Total |
5 Assignment Submission
5.1 Submit to Gradescope
Refer to the Project 1 instructions and adapt them for details of how to submit to Gradescope. In summary they are
- Type
make zipin the project directory to createp4-comlete.zip - Log into Gradescope, select Project 4, and upload
p4-complete.zip
5.2 Late Policies
You may wish to review the policy on late project submission which will cost 1 Engagement Point per day late. No projects will be accepted more than 48 hours after the deadline.
https://www.cs.umd.edu/~profk/216/syllabus.html#late-submission