Deep Thinking
Human-inspired thinking systems can solve complex logical reasoning problems.
Human-inspired thinking systems can solve complex logical reasoning problems.
We sonify (rather than visualize) what neurons respond to in a speech recognition model.

We construct clothing that makes the wearer invisible to common object detectors.

The origins of generalization in neural nets are mysterious and have eluded understanding. We gain an intuitive grasp on generalization through carefully crafted experiments.

We show that content control systems are vulnerable to adversarial attacks. Using small perturbations, we can fool important industrial systems like YouTube’s Content ID.

Adversarial training hardens neural nets against attacks, but it costs 10-100X more than regular training. We show how to do adversarial training with no added cost, and train a robust ImageNet model on a desktop computer in just a day.

A pattern has emerged in which the majority of adversarial defenses are quickly broken by new attacks. Given the lack of success at generating robust defenses, we are led to ask a fundamental question: Are adversarial attacks inevitable?
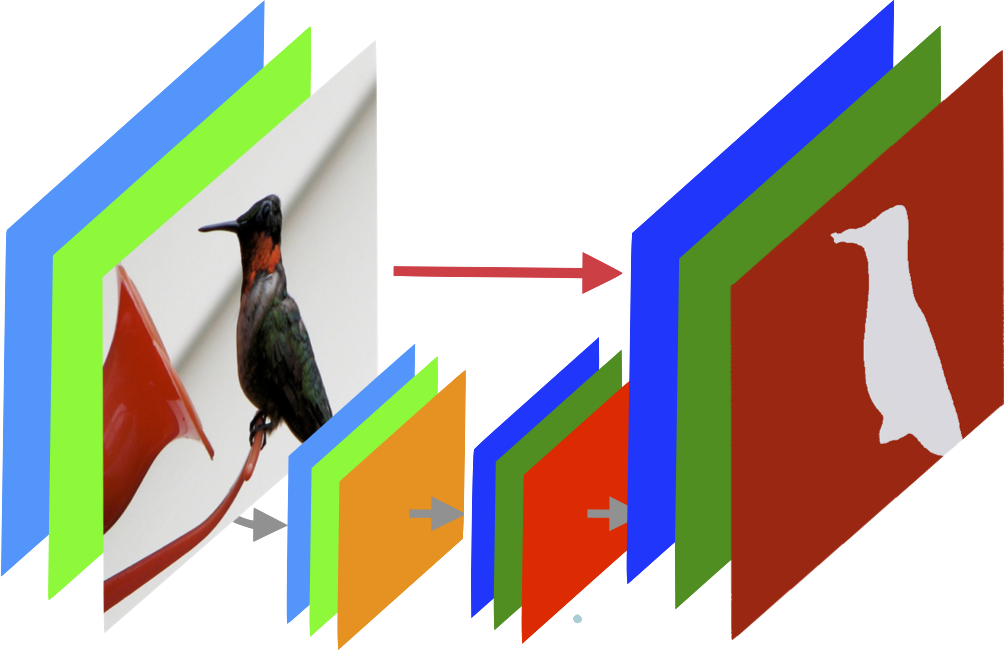
Stacked U-Nets are simple, easy-to-train neural architecture for image segmentation and other image-to-image regression tasks. SUNets attain state of the art performance and fast inference with very few parameters.

Data poisoning is an adversarial attack in which examples are added to the training set of a classifier to manipulate the behavior of the model at test time. We propose a new poisoning attack that is effective on neural nets, and can be executed by an outsider with no control over the training process.

It is well known that certain neural network architectures produce loss functions that train easier and generalize better, but the reasons for this are not well understood. To understand this better, we explore the structure of neural loss functions using a range of visualization methods.