Introduction to Parallel Computing (CMSC498X/CMSC818X)
Assignment 4: Charm++
Due: Monday November 23, 2020 @ 11:59 PM Anywhere on Earth (AoE)
The purpose of this programming assignment is to gain experience in parallel programming on a cluster and Charm++. For this assignment you have to write a parallel implementation of an iterative stencil computation.
We will use a two-dimensional (2D) Jacobi calculation to simulate heat diffusion. This calculation performs iterative sweeps (called timesteps) over a given array of values. The serial algorithm is described here and you have to implement its parallel version using C++ and Charm++.
Input/Initialization
Your program should read in a file containing the values that will be used to initialize the 2D array of doubles. A sample file is available here. This sample input corresponds to the initial conditions in the figure below. Two regions of size 128x128 are assigned initial values of 212 and 32 degrees F respectively to denote hot and cold zones. All remaining array elements are assigned an initial temperature of 72 degrees F.
Your program should take seven command line arguments: the name of the input data file, the number of iterations or timesteps, the X and Y sizes of the 2D data array, size_X, and size_Y, the X and Y sizes of the 2D chare array, num_chares_X, and num_chares_Y, and the name of the output csv file. To be more specific, the command line of your program should be: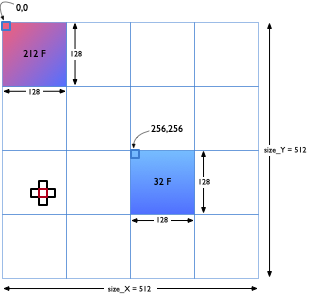
./jacobi2d <input filename> <# of timesteps> <size_X> <size_Y> <num_chares_X> <num_chares_Y> <output filename>
For the sample file above, size_X = size_Y = 512. The number of processes the program will run on is specified as part of the mpirun command with the -np argument.
mpirun -np <# of processes> ./jacobi2d <input filename> <# of timesteps> <size_X> <size_Y> <num_chares_X> <num_chares_Y> <output filename>
Serial Computation
At each timestep, the value in each cell (array element) is updated by averaging the values of its four neighbors and itself.
A[i, j] = (A[i, j] + A[i-1, j] + A[i+1, j] + A[i, j-1] + A[i, j+1]) * 0.2
You can assume periodic boundary conditions so the array elements at the edges will exchange data with elements on the opposite edge.
Output
Your program should write a single file (name set using the command line parameter) that contains comma separated values (up to three decimal points) of the 2D array. Each line in the file should correspond to one row of the array starting with i=0, j=0. This is the correct output file for the sample input file above after 100 timesteps. The only print from your program to standard output should be from the main chare that looks like this:
TIME: Min: 25.389 s Avg: 27.452 s Max: 41.672 s
Parallel Version
Use a 2D decomposition (both rows and columns) to parallelize the program. You can assume that size_X, size_Y, num_chares_X, and num_chares_Y will be powers of 2. You can also assume that num_chares_X >= 2, and num_chares_Y >=2, and that size_X and size_Y are much larger than num_chares_X and num_chares_Y.
Other sample inputs and outputs after 100 timesteps:
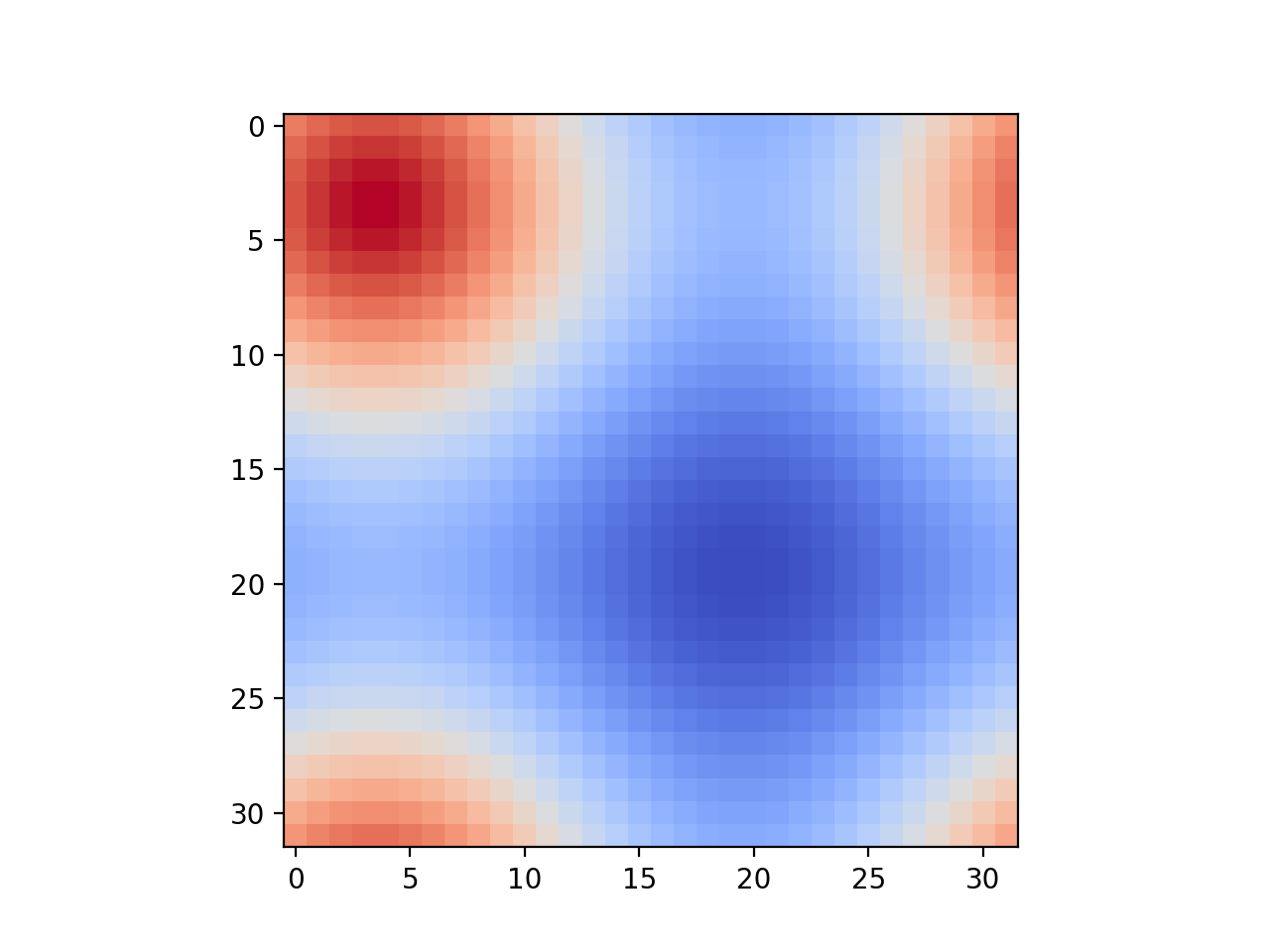
- Input 1 Output 1 size_X = 32, size_Y = 32, timesteps = 100
- Input 2 Output 2 size_X = 64, size_Y = 128, timesteps = 100
- Input 3 Output 3 size_X = 128, size_Y = 256, timesteps = 100
What to Submit
You must submit the following files and no other files:
jacobi2d.ci and jacobi2d.C: your parallel implementationMakefilethat will compile your code successfully on deepthought2 when using charmc. You can see a sample Makefile here. Make sure that the executable name is jacobi2d and do not include the executable in the tarball. NOTE: assignments without a Makefile will not be graded.- You must also submit a short report (LastName-FirstName-report.pdf) with performance results (a line plot). The line plot should present the execution times to run the parallel version on the sample 512x512 input file (for 1, 2, 4, 8, and 16 cores), with 4 chares per PE (core) for 100 iterations.
LastName-FirstName-assign4), compress it to .tar.gz (LastName-FirstName-assign4.tar.gz) and upload that to ELMS.Tips
- Quick deepthought2 primer.
- Use -g while debugging but -O2 when collecting performance numbers.
- You can use this Python script to visualize the output csv at any timestep.
Grading
The project will be graded as follows:
| Component | Percentage |
|---|---|
| Runs correctly on 1 process, 2x2 chares | 10 |
| Runs correctly on 16 processes, 8x4 chares | 20 |
| Runs correctly on 20 processes, 4x8 chares | 20 |
| Runs correctly on 32 processes, 8x8 chares | 20 |
| Speedup on 16 processes, 8x8 chares | 20 |
| Writeup | 10 |